| Cache Memory And The Caching Principle |
| Written by Harry Fairhead | ||||
| Thursday, 23 September 2021 | ||||
Page 2 of 3
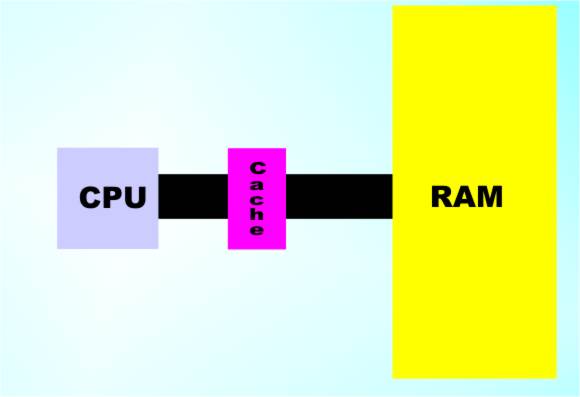
Cache RAMCache RAM is very simply a smallish chunk of RAM that can work as fast as the processor. If you could afford it, all of the memory in your machine could be cache RAM - only then we wouldn't call it cache just RAM. In practice only megabytes of cache RAM is generally used in a typical machine even though main memory my well be multiple Gigabytes.. What is the use of this tiny inadequate amount of RAM when compared with the Gigabytes a typical program needs? The answer is a very strange one but first we need to look a little more closely at how cache RAM is connected. It isn’t just an area of RAM separate from the main RAM. It is connected to the processor in such a way that the processor always tries to use the cache. When the processor wants to read a particular memory location it looks to see if the location is already in the cache. If it isn’t then it has to be read from main memory and there are wait states while the data is retrieved. Once the data is read it is kept in the cache and any subsequent request to read that particular location doesn’t result in a read from main memory and so any wait states are avoided. At this point you might be a little sceptical that cache memory is worth having. For example, when you want the content of a memory location for the first time you still have to wait for it. It is only when you want it a second time that you can have it fast. This seems like a worthless advantage. What might seem even worse is that simple cache systems do not perform cache writes. That is, when the processor wants to write to the memory it ignores the cache and puts up with the wait states. It all seems like complication and cost with virtually no pay off - but there you would be wrong. The reason you would be wrong is that you are not taking account of the way programs behave. The first thing to realise is that most memory accesses are reads. Why? The simple fact is that for every item of data written to the memory lots of locations storing the program, which the processor is obeying, are read. That is, 99% of all memory accesses are so that the processor can find out what to do next! For this reason the wait states generated when data has to be written to memory have a fairly minor impact on performance.
Cache gets between the CPU and the RAM
The next big surprise is that when a memory location has been read the chances are that it will be read again, and again. Every program has what is known as a “working set”. These are the memory locations that it re-uses time and time again. If you could set up a memory system that glowed every time a memory location was accessed then what you would see would be a patch of light that moved around as the program ran. There would be memory locations that would be accessed away from the working set but in the main this is where the action is. The reason for this behaviour is that programs tend to repeat actions – they run in loops – and this means that the same chunk of memory is read over and over again. To summarize
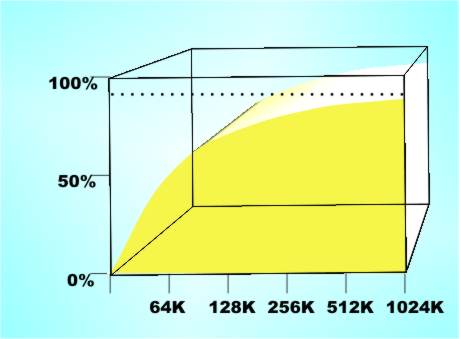
Hits and MissesWhen a read can be satisfied from the cache no wait states are generated and this is called a “cache hit”. When a location isn’t in the cache then we have a “cache miss” and the processor has to wait while the data is laboriously fetched from the RAM and stored in the cache. Now we come to the really surprising part. As long as the cache is larger than the working set of the current program the number of cache hits can be as high as 99% or better. That is, the impact of a slow main memory is reduced to less than 1% and so it isn’t really worth worrying about. The first time you hear this story you tend to accept it but then you start to think – no it can’t be so. For example, imagine that your program is processing a 1Mbyte image file such that each pixel is processed only once. Then in reading it you are going to generate one million cache misses and in writing it back out another million. That’s at least two million multiple wait states - surely the machine has to come to a halt! This is a misunderstanding of what the 99% statistic is telling you. For each data byte read and written 100 other memory locations will be read as part of running the program and on average these 100 will result in cache hits. It’s not that there aren’t a lot of cache misses per second, it’s just that there are also even more cache hits per second!
Hits versus cache size – a story of diminishing returns

<ASIN:0789736136> <ASIN:0123229804>
|
||||
| Last Updated ( Thursday, 23 September 2021 ) |