| A Robot Learns To Do Things Using A Deep Neural Network |
| Written by Mike James | |||
| Wednesday, 27 May 2015 | |||
|
We seem to be starting on the road to autonomous robots that learn how to do things and generalize. Watch as a robot learns how to use a hammer and adapts to changes in the setup.
Deep Neural Networks (DNNs) are well known for doing amazing things, but why are they not used more in robotics? If you have a neural network that can recognize things, why not couple it up to a robot's camera and let it control the robot? At the moment we have reached the point where if you look around the labs and the different work that is going on you come to the conclusion that there needs to be a consolidation and an integration to create something more than the sum of the parts. This is starting to happen. A team at UC Berkeley have implemented a DNN architecture that allows a robot to learn how to perform simple tasks. What is important about this is that while you can program a robot to perform simple tasks, and even teach them to do those tasks by example, a DNN has the power of generalization. In other areas of application DNNs tend to behave in ways that a human finds "understandable". That is, when they fail a human can see why they have failed and consider the failure not unreasonable. For example, if you show a DNN a photo of a miniature horse and it says that it is a dog - well you can see that it's a near miss rather than being catastrophically wrong as so many classical digital systems are prone to be. So if you teach a robot to do a job using a DNN then you have to hope that the same powers of generalization will allow the robot to do the same task in slightly different situations and this is what the UC Berkeley team has demonstrated does happen.
Pictured from left to right: Chelsea Finn, Pieter Abbeel, Trevor Darrell, and Sergey Levine...and BRETT.
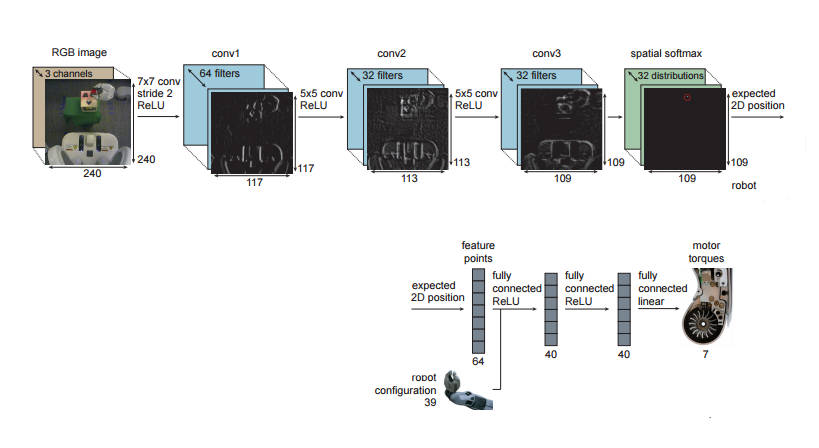
They have taken a Willow Garage PR2, called BRETT, for Berkeley Robot for the Elimination of Tedious Tasks, equipped with a single 2D video camera and placed a fairly complicated DNN between the camera and its motor controllers. The DNN is an interesting design. The raw RGB image is fed into three layers of convolutional DNNs and then into a softmax that makes a decision about what objects are at what locations. The activations of the final layer of the video processing network is converted to explicit 2D positions in the visual field and then passed on to three more fully connected DNNs. The input to the second DNN includes information about the current position of the robot and the final DNN outputs signals that drive the robots motors. Notice that in this setup there is no pre-programmed component that determines what the robot does. Training is performed mostly by reinforcement learning - a reward is supplied as the robot gets closer to doing what it needs to. The robot also learns useful visual features using the 3D positional information from the robot arm - the camera isn't calibrated in any way.
Of course training in any DNN is costly and so to make the whole training scheme reasonable the early vision layers were initialized using weights from a neural network trained on the ImageNet dataset. These provide a good starting point for general feature recognition. Next the robot trained itself to recognize the object involved in the task. To do this it held the object in its gripper and rotated the object to give different views from known positions. To avoid the neural network including the robot arm in the recognition task it was covered by a cloth! A similar pretraining initialization was used to narrow down the behaviors that could be learned. Finally the entire network was trained on the task. It is amazing enough that the robot learned to perform the task, but what is really interesting is the generalization observed when the task differs from the training examples. Take a look at the video:
Impressive though this is there is still a long way to go. As the paper points out: "The policies exhibit moderate tolerance to distractors that are visually separated from the target object. However, as expected, they tend to perform poorly under drastic changes to the backdrop, or when the distractors are adjacent to or occluding the manipulated objects, as shown in the supplementary video." The solution is probably more training in a wider range of environments. It is also suggested that more information could be included as input to the neural networks - haptics, auditory and so on. It is also suggested that a recurrent neural network, i.e a network with feedback, could provide the memory needed to allow the robot to continue if elements of the task are momentarily obscured. Clearly a lot more work is needed, but this is a demonstration of what can happen when you use neural networks as part of a system with senses and motor control. It is a step closer to the sort of robot sci-fi has been imagining since I Robot and before. More InformationEnd-to-End Training of Deep Visuomotor Policies. (pdf) To be presented at the IEEE International Conference on Robotics and Automation (ICRA) 2015 Seattle WA.
Related ArticlesGoogle's DeepMind Learns To Play Arcade Games Google's Neural Networks See Even Better The Deep Flaw In All Neural Networks
To be informed about new articles on I Programmer, install the I Programmer Toolbar, subscribe to the RSS feed, follow us on, Twitter, Facebook, Google+ or Linkedin, or sign up for our weekly newsletter.

Comments
or email your comment to: comments@i-programmer.info |
|||
| Last Updated ( Wednesday, 27 May 2015 ) |