| A Billion Neuronal Connections On The Cheap |
| Written by Mike James | |||
| Monday, 24 June 2013 | |||
|
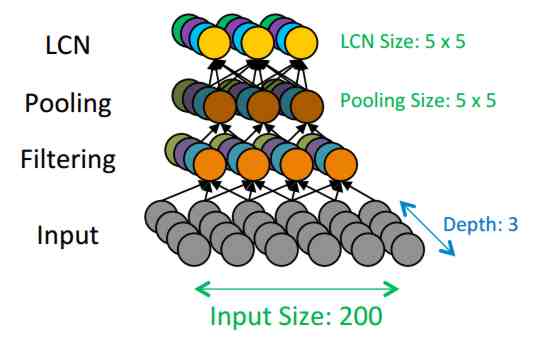
Recent advanced in deep neural networks have been very encouraging to AI researchers but there is a snag. To train the number of neurons needed costs big money but now Google's AI team has a way of getting you back in the game - at only $20,000. Deep Neural Networks (DNNs) are currently the great hope of AI, but if you want to follow in Google's footsteps and train the sort of network that can extract natural features such as faces and cats from video then you will need deep pockets as well as networks. DNNs are very easy to implement, but very costly to train. The Google face network needed 1000 computers and cost in the order of $1 million. This is something of a barrier to both research and industry. For example, if you plan to bring out an alternative to the Kinect's skeleton tracking then you need to think in terms of big training. Now you can aspire to join in the DNN revolution without having to invest in a super computer - although the machine you need is still fairly special. A paper published by a research team at Stanford, including Andrew Ng who led the Google DNN work, describes a configuration of the off-the-shelf components that can handle 1-billion parameter networks with just three machines and training is complete in a couple of days. It can also scale to something that can handle 11-billion connections for $100,000 using 16 machines. You can probably guess that the secret to this new hardware is the use of GPUs: "In this paper, we present technical details and results from our own system based on Commodity Off -The-Shelf High Performance Computing (COTS HPC) technology: a cluster of GPU servers with Infinband interconnects and MPI." The big 16-machine cluster is described as: "Our cluster is comprised of 16 servers, each with 2 quad-core processors. Each server contains 4 NVIDIA GTX680 GPUs and an FDR Infinband adapter. The GPUs each have 4GB of memory and are capable of performing about 1 TFLOPS (single-precision) with well-optimized code. The Infinband adapter connects to the other servers through an In finband switch, and has a maximum throughput of 56 Gbps along with very low end-to-end latency (usually microseconds for small messages)." The GPUs are coded using CUDA - what else? The DNN that the system implements is built from standard macro-layers. Each macro-layer has three sub-layers of neurons - linear filtering, polling and local contrast normalizing. Each macro-layer is repeated 3 times to give a 9-layer network. The structure of the networks and the implementation of the training algorithm is tweaked so as to make it more efficient to compute using the GPU architecture.
The system was testing by replicating the Google video experiment; 10 million You Tube thumbnails at 200x200 were fed to the network which then learned to recognize faces and cats among other things. The network with 1.8 billion parameters worked well. Moving on to bigger things the researchers then trained a network with 11 billion parameters, but this did slightly worse than the smaller network. This is a well known effect in DNN and it is an indication that the perhaps the network is being over fitted to the data - the solution is more data or better training algorithms.
Patterns that you get out of the network after training - a sort of indication of what they consider to be representative features learned.
But now we have the hardware to allow experimentation: "With our system we have shown that we can comfortably train In many ways this sort of work is much more important than the emphasis on quantum computer and other types of "super" computers. We need machines better optimized to DNN learning. More InformationDeep learning with COTS HPC systems (pdf) Related ArticlesDeep Learning Powers BING Voice Input Google Explains How AI Photo Search Works Near Instant Speech Translation In Your Own Voice Google's Deep Learning - Speech Recognition A Neural Network Learns What A Face Is
To be informed about new articles on I Programmer, install the I Programmer Toolbar, subscribe to the RSS feed, follow us on, Twitter, Facebook, Google+ or Linkedin, or sign up for our weekly newsletter.
Comments
or email your comment to: comments@i-programmer.info

|
|||
| Last Updated ( Sunday, 30 June 2013 ) |