| Neural networks |
| Written by Editor | |||||||
| Friday, 28 August 2009 | |||||||
Page 3 of 3
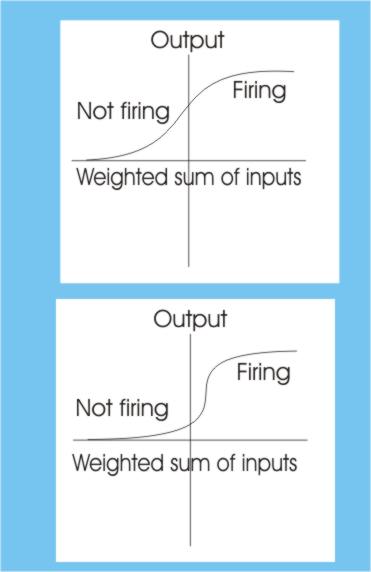
The problem is that you don’t really know which neuron to blame for the current error in the output. One big change that has to be made so that you can track back the blame is that you can’t use a simple threshold function. Now you have to use a function which allows the neuron’s output to change smoothly from not firing to firing. The neuron’s one/off characteristics are retained, however, by making the function approximate a sudden change.
By making the smooth change more sudden you can approximate a threshold Back propagationUsing a neuron of this sort you can implement the learning algorithm no matter how complicated the network by:
The details are a bit more complicated because the amount of the error passed back also depends on the shape of the threshold function but this is the general idea. The most commonly used name for this method is “back propagation” because the errors are passed back through the network in the same way as the input propagates forward to produce the output. Using back propagation a neural network can learn anything you want it to learn. It most certainly can learn the 0,1 and 1,0 problem without any outside help! At this point it all looks as if the problems of AI are solved. If you want an AI system to respond to English commands simply get a large neural network and start training it to recognize words. This was very much the hype that followed in the wake of the rediscovery of multi-layer neural networks but the truth isn’t quite as promising. A neural network can learn anything you care to throw at it but it takes ages to train it. I suppose you could say neural networks learn very slowly. In addition we have said nothing about generalization. That is, if a neural network learns to recognize a teapot, a particular teapot, will it recognize another similar teapot that it has never seen! What is more you might now be thinking that we can start building really complicated networks of artificial neurons, artificial brains say, and teach them really complicated things. There is nothing quite like Kolmogorov’s theorem to bring us back down to earth. This says that anything a neural network can learn can be learned by a network with only two layers, i.e. only two neurons between input and output. So we don’t have a recipe for a brain because clearly our brains use deeper networks than this! What is more it seems likely that our brains use networks that have feedback connections and what these are for is another big problem as the sort of networks that we can train using back propagation cannot have feedback and in fact don’t need feedback. Clearly we still have some way to go. 
<ASIN:1846283450> <ASIN:0262181207> <ASIN:0262631105> |
|||||||
| Last Updated ( Saturday, 19 March 2011 ) |