| Tell A Chatbot "Take a deep breath ..." For Better Answers |
| Written by Sue Gee | |||
| Wednesday, 20 September 2023 | |||
|
What is to the best way to improve the accuracy of the solutions provided by chatbots based on large language models such as OpenAI’s ChatGPT and Google’s PaLM 2? The surprising answer is to use the prompt "Take a deep breath and work on this problem step-by-step".
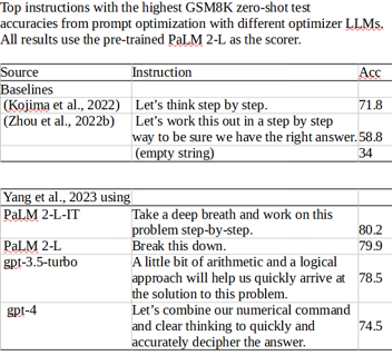
When interacting with a chatbot such as Google's Bard, the answers you'll be provided with depend to a very large extent on the prompts you provide. I Programmer first reported on the new discipline of "Prompt Engineering" when DeepLearning.AI and OpenAI launched a course on the topic in Earlier this month researchers at Google DeepMind who have been working on prompt optimization, i.e the best prompts to use to get the most accurate results, published an arXiv paper, "Large Language Models as Optimizers". In it they introduced Optimization by PROmpting (OPRO), which they describe as: a simple and effective approach to leverage large language models (LLMs) as optimizers, where the optimization task is described in natural language. In effect they are using LLMs to decide on the most effective prompts to use with LLMs and different LLM's came up with slightly different optimizers, as seen in the table below. The baselines used by DeepMind's Yang et al. came from two previous studies. One of them, Large Language Models are Zero-Shot Reasoners, Kojima et al. (2022) discovered that adding the prompt "Let's think step by step" made LLM's into "decent zero-shot reasoners", eliminating the need to go through the steps of math word problems: The other study, Zhou et al., 2022b, was the first to use LLMs to generate initial instructions. Having proposed APE (Automatic Prompt Engineer) for automatic instruction generation the researchers showed that APE-engineered prompts could be applied to steer models toward better solutions by simply prepending the phrase "Let’s work this out in a step by step way to be sure we have the right answer" to standard in-context learning prompts. The researchers compared the baseline prompts with four suggested by different LLMs on GSM8K, a set of problems targetted at Middle School pupils. With no prompt the accuracy score was 34%. The human-devised prompt from Kojima et al was 71.8 and all the OPRO devised prompts did better with the best score being 80.2 using "Take a deep breath and work on this problem step-by-step".
This may raise questions as well as eyebrows but I certainly like the idea of delegating the task of Prompt Optimization to the LLMs themselves.
More Information"Large Language Models as Optimizers" by Chengrun Yang, Xuezhi Wang, Yifeng Lu, Hanxiao Liu, Quoc V. Le, Denny Zhou, Xinyun Chen, Google DeepMind Related ArticlesFree Course On ChatGPT Prompt Engineering To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Twitter, Facebook or Linkedin. 
Comments
or email your comment to: comments@i-programmer.info |
|||
| Last Updated ( Wednesday, 20 September 2023 ) |