| Speech Recognition Breakthrough |
| Written by Mike James |
| Monday, 29 August 2011 |
|
Microsoft Research is claiming a breakthrough in speech recognition and it is a very interesting one because it promises to generalize to other fields. One of the earliest attempts at general speech recognition was to use the then new Artificial Neural Networks (ANN). These worked well but not well enough and slowly but surely researchers tailored the techniques to take account of the particular structure in the data. The most successful approach was the ANN Hidden Markov Model (ANN-HMM) which used the fact that there are correlations between features. However, this approach couldn't be improved sufficiently to produce something practical and the reason was the way neural networks were trained. This resulted in neural networks being replaced by something more specific still and the context-dependent Gaussian mixture model (GMM) came to be the bright hope of speech recognition. This replacement of neural networks by less general techniques more tailored to the particular data being worked with, was a common feature across AI. You could say that interest in ANNs slumped. However, in 2006 Geoffrey Hinton and others developed a theory of Deep Neural Networks (DNNs). This essentially proposed a layered structure in which each layer being trained in turn, so speeding up the training. If you want to know more about DNNs then the best introduction is the Google Tech Talk by Geoffrey Hinton in 2007:
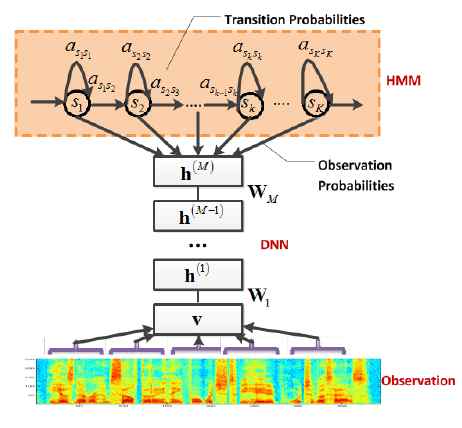
For this new approach, teams led by Dong Yu at Microsoft Research Redmond and Frank Seide at Microsoft Research Asia decided to try a DNN for speech recognition but using not phonemes but much smaller units of speech - senones. This had been tried with standard ANNs but the problem was the time it took to learn the huge amount of data. The actual design used in the new model was a context-dependent DNN-HMM and this was faster to train. A GPU implementation was also used to speed things up.
The DNN architecture
The new approach was tested using Switchboard a standard speech to text benchmark. After 300 hours of training with a model that incorporated 66 million interconnections the results were remarkable. The error rate of 18.5% represented a 33% improvement over traditional approaches to speaker independent speech recognition. The work is going to be presented at Interspeech 2011 but you can read the paper now. While the method still isn't good enough for real use, the improvement in performance is a big step forward in speech recognition. It also marks a return to the neural network learning model. It does look as if we are seeing the beginnings of the third neural network revolution - the first being single-layer models, the second being multi-layer models and now we have multi-layer models with structured learning. More InformationConversational Speech Transcription
If you would like to be informed about new articles on I Programmer you can either follow us on Twitter or Facebook or you can subscribe to our weekly newsletter. 
|
| Last Updated ( Friday, 09 November 2012 ) |