| Realtime Facial Tracking and Animation |
| Written by Alex Armstrong |
| Saturday, 16 August 2014 |
|
A video from SIGGRAPH 2014 presents a fully automatic approach to realtime facial tracking and animation which doesn't require calibration for different individuals and seems suitable for deployment in consumer-level applications. See the video to appreciate how good it is at getting an avatar to follow your facial expressions.
This research comes from the Graphics and Parallel Systems Lab of Zhejiang University, China. What is impressive about the demo is that, rather than an RGBD camera such as the Kinect, it employs a single "normal" video camera (webcam) that are widely available on PCs and mobile devices. You need to see the video of it in action to appreciate how good it is and how it could be used to implement avatars, virtual reality, telepresence and so on...
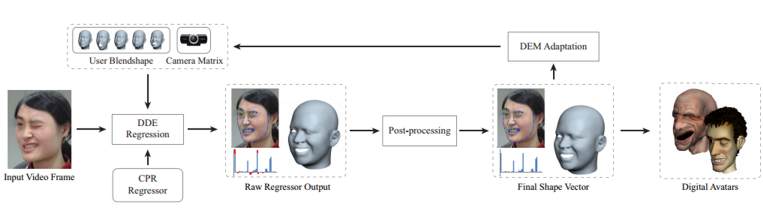
To quote from the paper Displaced Dynamic Expression Regression for Real-time Facial Tracking and Animation authored by Chen Cao, Qiming Hou and Kun Zhou, the automatic approach employed: learns a generic regressor from public image datasets, which can be applied to any user and arbitrary video cameras to infer accurate 2D facial landmarks as well as the 3D facial shape from 2D video frames, assuming the user identity does not change across frames. The inferred 2D landmarks are then used to adapt the camera matrix and the user identity to better match the facial expressions of the current user. The regression and adaptation are performed in an alternating manner, effectively creating a feedback loop. With more and more facial expressions observed in the video, the whole process converges quickly with accurate facial tracking and animation.
(click to enlarge)
As indicated in the workflow diagram above, the process uses a regression-based algorithm with the DDE (Displaced Dynamic Expression) model which simultaneously represents the 3D shape of the user’s facial expressions and the 2D facial landmarks which correspond to semantic facial features in video frames. The DEM (Dynamic Expression Model) adaptation step corrects the camera matrix for the current users, thus eliminating the need for calibration.
More InformationDisplaced Dynamic Expression Regression for
Related ArticlesAn algorithm for face transfer
To be informed about new articles on I Programmer, install the I Programmer Toolbar, subscribe to the RSS feed, follow us on, Twitter, Facebook, Google+ or Linkedin, or sign up for our weekly newsletter.

Comments
or email your comment to: comments@i-programmer.info
|
| Last Updated ( Saturday, 16 August 2014 ) |