| MIcrosoft's Project Oxford AI APIs For The REST Of Us |
| Written by Mike James | |||
| Friday, 01 May 2015 | |||
|
An announcement that has mostly gone unnoticed at this year's Build is Project Oxford - a set of REST APIs that give you some advanced AI in a really easy-to-use form. The big problem with incorporating AI into your own project is that it is not only complicated but time consuming. Even if you understand the theory to build your own working AI, you need a lot of data and a lot of time spent training it to produce a good performance. Of course, if what you need is something that tackles a standard task, you could use something that had been trained by someone else. This is the idea behind Microsoft's Project Oxford. It offers pre-trained AI services in four categories - Face, Speech, Vision and Language Understanding. Each of the services is available as REST APIs and there are SDK s for .NET and Android, and additionally for iOS for the speech API. However, given that the API is REST-based there really isn't a big problem in using the service from any language or platform as long as it has Internet access and an HTTP library.
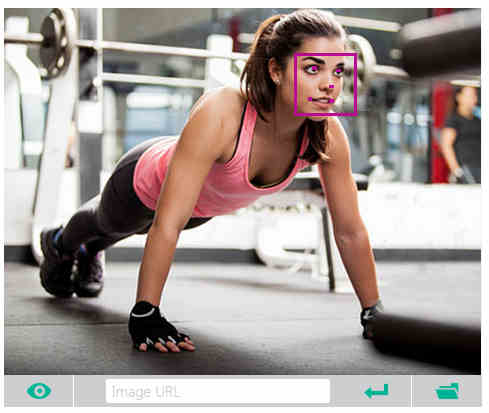
The Face API can be used for face detection, i.e. return bounding boxes for each face in the image; face verification; i.e. is this face the same as another face image; face searching, i.e. find this this face in this set of images; face clustering, i.e. put faces into similar groups; and finally face identification, i.e. find a given face in a database of faces. The Speech API does speech to text from a real time streaming audio source. It also offers speech intent recognition, i.e. recognize a spoken command, and text to speech. The Vision API isn't quite up to general object recognition and tracking, but it is still very useful. You can ask it to analyze an image and return a general categorization of what type of image it is. It can also detect "adult" and "racy" images. The other two main features are intelligent cropping to produce a thumbnail and optical character recognition. The Language API is the most flexible and technically demanding. You can use it to create language understanding models that can be used with the speech API and its intent recognition. You can opt to deploy your models either to an HTTP endpoint or to a device.
Some of the API features have live demos that you can use to try things out without having to write any code. In the case of the Face API you can either use the sample image or upload your own jpeg, png, gif or bmp. The results are returned by the API as JSON data, but the demos use the data to present them in a way that is easier to digest, i.e. actually drawing the bounding boxes on the image. This all sounds great and it provides a very easy way to add AI to your apps or web pages. So what is the downside? All of the APIs are delivered via the Azure cloud and one of the benefits that Microsoft is going to get from you using them is another reason why Azure is important to you and of course you will need an Azure account. At the moment you have to obtain a key to make use of the service and while it is in beta it is free and subject to limits. For example the Vision API is restricted to 20 transactions per minute and 5000 transactions per month. Not too bad for testing purposes, but there is no guidance as to how much the final service will cost. The Oxford team say that it is working on establishing prices and clearly it would be wise not to invest too much time in developing anything much before these are finalized. Of course, for many uses the task of connecting with the API is so easy that would be well worth trying out even if the price did turn out to be too high.
More InformationRelated ArticlesAzure Machine Learning Service Goes Live Machine Learning Goes Azure - Azure ML Announced Tracking.js Computer Vision In The Browser Alien FaceHugger v Predator - Face Tracking Hots Up
To be informed about new articles on I Programmer, install the I Programmer Toolbar, subscribe to the RSS feed, follow us on, Twitter, Facebook, Google+ or Linkedin, or sign up for our weekly newsletter.

Comments
or email your comment to: comments@i-programmer.info |
|||
| Last Updated ( Friday, 01 May 2015 ) |