| AlphaGo Has Lost A Game - Score Stands At 3-1 |
| Written by Mike James | |||
| Sunday, 13 March 2016 | |||
|
AlphaGo's human opponent Lee Se-dol has won the fourth game in the Deep Mind Challenge, proving that man can still outwit machine. Here's our updated story on this groundbreaking match. Losing a game doesn't affect the final outcome of the 5-game match, but it is important psychologically, not only for Lee and his fellow professional Go players but also for AI researchers. There is still something to play for! At the press conference after the match, Deep Mind CEO Demi Hassabis said he was very happy with the outcome: " ... this is why we came here — to test AlphaGo to its limits."
The scoreboard shows that Lee won after 180 moves. As in previous matches, he had used up all of his time and two periods of byō-yomi overtime. Speaking after the match Lee Se-dol said: "I've never been congratulated so much just because I won one game." According to the Google blog: Lee Sedol made a comeback today [Saturday, March 12] after three consecutive losses, to beat AlphaGo in the fourth game. Playing as white, Lee won by resignation after 180 moves. AlphaGo held a strong position for the first half of the game, but commentators noted that Lee Sedol played a brilliant move 78, followed by a mistake by AlphaGo at move 79. Here is what the American and Korean commentators had to say. The 9-dan Go player Michael Redmond, stated
“Today’s game was another example of AlphaGo playing a very interesting, good game. However, move 78 by Lee Sedol was really brilliant — and enabled him to win.“
Song Taegon, also rated 9-dan, said:
“It seems Lee Sedol can now read AlphaGo better and has a better understanding of how AlphaGo moves. For the 5th match, it will be a far closer battle than before since we know each better. Professional Go players said that they became more interested in playing Go after witnessing AlphaGo’s innovative moves. People started to rethink about moves that were previously regarded as undesirable or bad moves. AlphaGo can help us think outside of the box in Go games.“ Demi Hassabis tweeted:
Saturday March 12 Google's AlphaGo has won the Deep Mind Challenge, by winning the third match in a row against the 18-time world champion Lee Se-dol Here's our updated story on this historic breakthrough for AI.
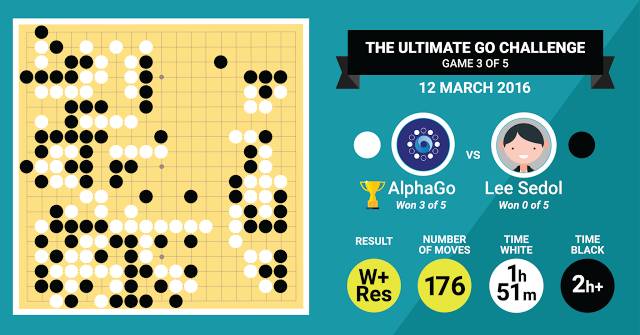
The board position at the end of the third game looks startlingly different. This time AlphaGo made a win by resignation after 176 moves. Lee used up all of his time and two periods of byō-yomi overtime, while AlphaGo had 8:31 left on the clock. According to Google: AlphaGo created a large territory on the board but Lee Sedol used a few innovative tactics to start a huge all-or-nothing kō fight and complicate the situation. In the resulting kō fight, AlphaGo prevailed. Summing up this third match in the series of 5. which is taking place in Seoul, Lee Hyunwook, 8-dan, Korean commentator said: “Lee Sedol played well. As a professional player myself, I’d like to show my respect to his three consecutive games against AlphaGo, which played almost perfectly. Lee made a few diverse moves at the end of today’s game to understand more about AlphaGo. I look forward to remaining games as well.” Michael Redmond, 9-dan, the American commentator said: “It’s arguable that in the first two games Lee Sedol was playing differently than his true style, trying to find a weakness in the computer. Today Lee was definitely playing his own game, from his strong opening to the complicated moves in the final kō. AlphaGo was ready for everything, including the kō fights, and was able to take the win. I’d like to congratulate the people who actually made this accomplishment possible, because it’s a work of art.” Demis Hassabis, DeepMind's founder and CEO and the person who initiated the AlphaGo project tweeted:
Although AlphaGo has already won the match there are still two rounds to be played in the 5-game series to determine the final match score. Game Four, will be on Sunday, March 13, and the final one takes place on Tuesday, March 15. There is certainly something left for Lee Se-dol to play for - can the world's best human beat DeepMind's algorithmic approach.
Friday March 11
Following on from its success in the first match, which is reported below, AlphaGo again a number of creative moves that surprised the expert commentators in the second one. The American commentator said: “I was impressed with AlphaGo’s play. There was a great beauty to the opening. Based on what I had seen from its other games, AlphaGo was always strong in the end and middle game, but that was extended to the beginning game this time. It was a beautiful, innovative game.”
“During the first match, Lee Sedol made difficult moves to agitate AlphaGo, but failed to do so. Today, he tried the opposite — he played safe and entered the endgame. While using his byō-yomi periods, he made some mistakes, which I think caused the defeat.” This second game lasted over 4 hours with both Lee Sed-ol and AlphaGo using their entire two-hours of time plus more known as byō-yomi overtime.
You can see a 90 second summary of the game in the following video which is much better than the video of game one.
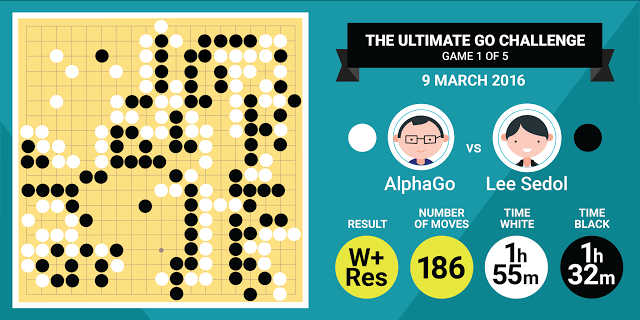
Wednesday March 9 Google's DeepMind AlphaGo program has won the first game in its match against legendary Go player, Lee Se-dol. OK, it may only be the first game in a series of five, but it is such a big step forward it is the AI equivalent of landing on the moon.
You can't really blame Demis Hassabis for being slightly over the top - it really is this amazing. Perhaps what is more amazing is that the techniques that have been used to create AlphaGo are essentially the approaches that AI has been working on for a long time - neural networks and reinforcement learning. This doesn't mean that getting it right has been easy, but this is all a case of "more" rather than "radically different". The architecture of the network, called AlphaGo and designed by Google's Deep Mind team, is novel in that it uses two distinct neural networks in a traditional reinforcement learning "actor-critic" arrangement. The first network picks possible moves and the second evaluates them in terms of how much advantage the move gives in the future. This approach allowed AlphaGo to learn from 30 million human games of Go and then go on to refine its performance by playing millions of games against itself. Back in October, AlphaGo beat the European Go Champion (Google's AI Beats Human Professional Player At Go) and Google arranged a tougher test of the software in the style of the classic man meets machine chess matches. The world champion, South Korea's Lee Se-dol, was offered a five game match in Seoul with a prize of $1 million and now this match has begun.
AlphaGo won the first game. According to the DeepMind press release: AlphaGo takes the first game against Lee Sedol. They were neck-and-neck for its entirety, in a game filled with complex fighting. Lee Sedol made very aggressive moves but AlphaGo did not back down from the fights. AlphaGo took almost all of its time compared to Lee Sedol who had almost 30 minutes left on the clock.
You can watch the recording of the live stream below - the match starts at about 27 minutes in and you need to be warned it isn't a very good video with lots of glitches and terrible commentators:
According to game experts, Lee seemed to have the upper hand for most of the game, but in the last 20 minutes AlphaGo produced moves that made a win inevitable. Worryingly some analysts claim that an early move was something a human would never have played. Could it be that this first match win is due to the human player not understanding the nature of his machine opponent? It is alleged that the famous chess win by Deep Blue over Kasparov was due to a bug causing a random move to be played which Kasparov failed to understand and attributed to superior intelligence. He is said to have lost the game because of the anxiety it caused. If this is the case then you can expect Lee Se-dol to improve as he gets used to his opponent. It really doesn't matter if AlphaGo unnerved Lee by playing in a non-human manner. The fact that a program is taking on a top level human player and being taken seriously is still the AI equivalent of a moon landing. Watch out for the update on the remaining matches.
More InformationMastering the game of Go with deep neural networks and tree search Related ArticlesGoogle's AI Beats Human Professional Player At Go Google's DeepMind Learns To Play Arcade Games Google Buys Unproven AI Company Deep Learning Researchers To Work For Google Google's Neural Networks See Even Better
To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on, Twitter, Facebook, Google+ or Linkedin.

Comments
or email your comment to: comments@i-programmer.info
|
|||
| Last Updated ( Tuesday, 15 March 2016 ) |