| Elastic MapReduce Demo Shows How to Handle Large Datasets |
| Written by Kay Ewbank | |||
| Wednesday, 17 April 2013 | |||
|
Amazon WebServices has posted a video on YouTube showing how you can get started using Elastic MapReduce to handle large datasets quickly.
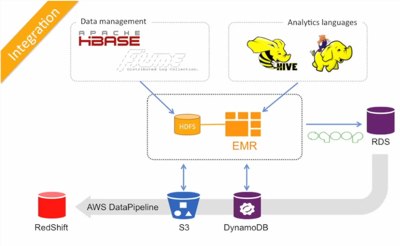
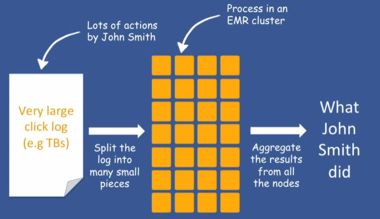
The webinar, which is around 50 minutes long, show how to set up an Elastic MapReduce (EMR) job flow to analyze application logs, then goes on to show how to perform Hive queries against it. EMR is a web service from Amazon that you can use to process very large amounts of data. It makes use of a hosted Hadoop framework running on Amazon Elastic Compute Cloud (Amazon EC2) and Amazon Simple Storage Service (Amazon S3). This means you can provision as much capacity as you need for tasks such as web indexing or data mining.
You don’t have to worry about the setup, management or tuning of the Hadoop clusters, the service takes care of that side of things. You can spin up large Hadoop job flows, start the processing in minutes, and once the job flow finishes, the service tears down your instances unless you tell it otherwise.
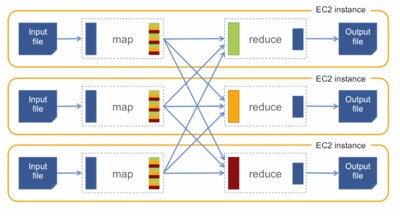
A job flow is made up of steps that manipulate the data. Each step is a Hadoop MapReduce application implemented as a Java jar or a streaming program written in Java, Ruby, Perl, Python, PHP, R, or C++. For example, to count the frequency with which words appear in a document, and output them sorted by the count, the first step would be a MapReduce application which counts the occurrences of each word, and the second step would be a MapReduce application which sorts the output from the first step based on the counts.
The web service interfaces let you build processing workflows, and programmatically monitor the progress of running job flows. You can also put together apps using features such as scheduling, workflows and monitoring. The webinar shows the best ways to organize your data files on Amazon Simple Storage Service (S3), then goes on to show how clusters can be started from the AWS web console and command line, and how to monitor the status of a Map/Reduce job. The latter part of the demo shows how Hive provides a SQL like environment. Hive is Apache’s open source data warehouse and analytics package that you work with using a SQL-based language. Hive goes beyond standard SQL with additional map/reduce functions and support for user-defined data types like Json and Thrift.
More InformationRelated ArticlesPig and Hadoop support in Amazon Elastic MapReduce
To be informed about new articles on I Programmer, install the I Programmer Toolbar, subscribe to the RSS feed, follow us on, Twitter, Facebook, Google+ or Linkedin, or sign up for our weekly newsletter.
Comments
or email your comment to: comments@i-programmer.info

|
|||
| Last Updated ( Wednesday, 17 April 2013 ) |