| Columbia Creates Data Set Cleaner |
| Written by Kay Ewbank | |||
| Tuesday, 06 September 2016 | |||
|
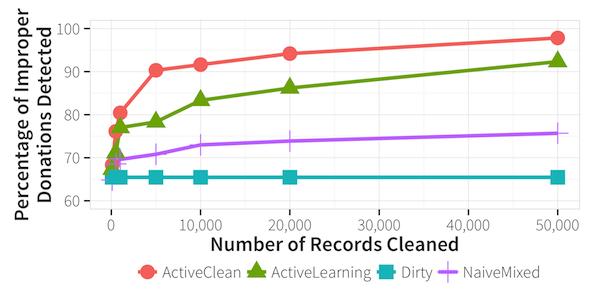
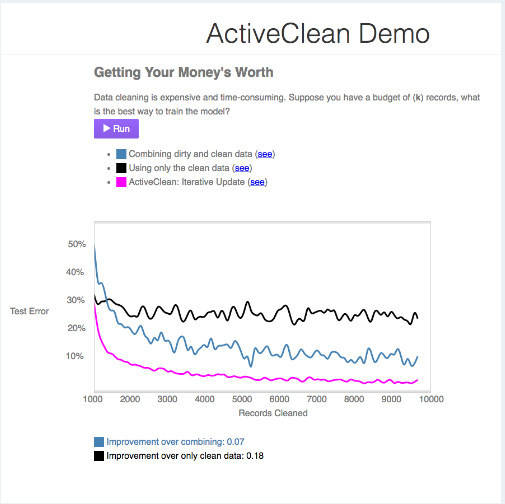
A tool that cleans big data sets of dirty data has been developed at ColumbIa University and University of California at Berkeley. ActiveClean is a system that uses machine learning to improve the process of removing dirty data. It analyzes a user's prediction model to decide which mistakes to edit first, while updating the model as it works. With each pass, users see their model improve. The problem of errors in big data sets arises from the fact that they are still mostly combined and edited manually. The task of removing incorrect or dirty data is currently handled either using data-cleaning software such as Google Refine and Trifacta, or custom scripts developed for specific data-cleaning tasks. The developers of ActiveClean estimate that this process consumes up to 80 percent of analysts' time as they hunt for dirty data, clean it, retrain their model, and repeat the process. Because it is impossible to clean the whole of very large data sets, what usually happens is that a random subset is cleaned. This can introduce statistical biases that then skew models into producing misleading results. ActiveClean avoids these problems by using machine learning to remove the human element from the stages of finding dirty data and updating the model. It analyzes a model's structure to understand what sorts of errors will throw the model off most, looks for data that would cause those errors, and cleans just enough data to show that a model will be reasonably accurate. In tests on a database of corporate donations to doctors, when the data was used without any data cleaning, a model trained on this dataset could predict an improper donation just 66 percent of the time. ActiveClean raised the detection rate to 90 percent by cleaning just 5,000 records. An alternative technique, active learning, required 10 times as much data, or 50,000 records, to reach a comparable detection rate.
"Dirty data is pervasive and prevents people from doing useful things," said Eugene Wu, a computer science professor at Columbia Engineering and a member of the Data Science Institute who helped develop ActiveClean as a postdoctoral researcher at Berkeley's AMPLab and has continued this work at Columbia. ActiveClean is written in Python and includes the core ActiveClean algorithm, a data cleaning benchmark, and (in the future), an dirty data detector.
The development team will present its research on Sept. 7 in New Delhi, at the 2016 conference on Very Large Data Bases. More InformationRelated ArticlesDevs Exploring Emerging Technologies Linux Data Science Virtual Machine
To be informed about new articles on I Programmer, sign up for our weekly newsletter,subscribe to the RSS feed and follow us on, Twitter, Facebook, Google+ or Linkedin.

Comments
or email your comment to: comments@i-programmer.info |
|||
| Last Updated ( Tuesday, 06 September 2016 ) |