| Oracle Big Data SQL |
| Written by Kay Ewbank |
| Monday, 21 July 2014 |
|
A unified query tool that you can use to ask questions across mixed SQL, Hadoop and NoSQL data sources has been released by Oracle. Oracle Big Data SQL will be available ‘in a few months’, initially for the Oracle Big Data Appliance platform. Versions for Oracle Database on commodity hardware are planned for the future.
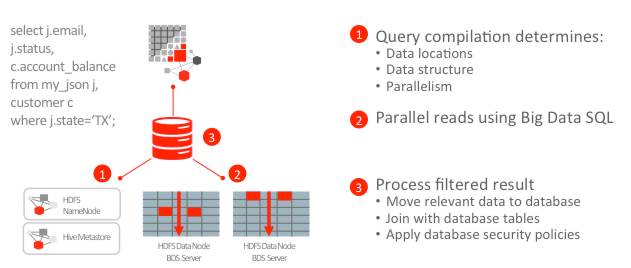
The software lets you use Oracle SQL to write queries against Hadoop and NoSQL, and has a “Smart Scan service” that Oracle says minimizes data movement and maximizes performance. The utility uses Oracle Exadata Smart Scan technology. It processes SQL queries at the Hadoop storage level, scans the data, and brings back only the relevant data to the end user. This cuts down on the data that has to be transferred. Smart Scan for Hadoop adds a new service that is then co-resident with HDFS DataNodes and YARN NodeManagers in the Hadoop system. Queries from the new external tables are sent to these services to ensure that reads are direct path and data-local. Smart Scan also cuts down on what data is returned by only sending the columns that are included in the required results, and by selecting the rows at source so non-relevant data is removed. “By having Smart Scan on Hadoop, you have cut the amount of data you otherwise would have moved by 99 percent,” according to Paul Sonderegger, big data strategist at Oracle.
Oracle Big Data SQL treats the non-SQL data sources as external tables to a ‘normal’ Oracle database. The way the external tables are handled is to use the Hive metastore or user definitions to determine both parallelism and read semantics. That means that if a file in HFDS is 100 blocks, Oracle database understands there are 100 units which can be read in parallel. If the data was stored in a SequenceFile using a binary SerDe, or as Parquet data, or as Avro, that is how the data is read. Big Data SQL uses the exact same InputFormat, RecordReader, and SerDes defined in the Hive metastore to read the data from HDFS. This avoids the problems usually caused by treating external tables as flat files rather than distributed data, resulting in poor parallelism and removing the value of schema-on-read. Oracle Big Data SQL will be packaged as an option for the firm's Big Data Appliance platform, in a similar way to the Big Data connectors toolset. The software will be available in Q3 2014.
More InformationOracle Big Data SQL: One Fast Query, All Your Data Related Articles100 x Faster Queries Promises Oracle Oracle Unveils Exalytics for Business Intelligence
To be informed about new articles on I Programmer, install the I Programmer Toolbar, subscribe to the RSS feed, follow us on, Twitter, Facebook, Google+ or Linkedin, or sign up for our weekly newsletter.

Comments
or email your comment to: comments@i-programmer.info |
| Last Updated ( Monday, 21 July 2014 ) |