| Cassandra 2.0 Available |
| Written by Kay Ewbank | |||
| Tuesday, 10 September 2013 | |||
|
Apache has released Cassandra 2.0, the new version of the NoSQL distributed database. Improvements include lightweight transactions, triggers and enhancements to the Cassandra Query Language. Apache Cassandra has grown in popularity and is now used in applications at Adobe, CERN, Comcast, eBay, GoDaddy, HP, IBM, Instagram, Netflix, Plaxo, and Sony.
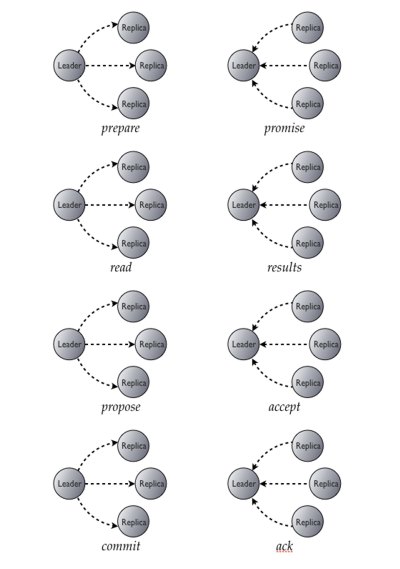
According to the Apache Software Foundation announcement of the new version, the lightweight transaction support means Cassandra now has operation linearizability similar to the serializable isolation level offered by relational databases, which prevents conflicts during concurrent requests. The DataStax Developer blog has a good description of how lightweight transactions in Cassandra work, but essentially, the system uses the Paxos consensus protocol. Essentially, a node proposes making a change to a value. The proposal is sent to participating replicas, and those replicas promise not to accept any other proposed changes (for the moment). If a majority of the nodes promise to accept the proposer’s change, it can proceed to do the change. However, if the majority of the replicated nodes included an earlier proposed change with their response, then that is the value the proposing node goes with. Cassandra extends the Paxos consensus protocol with a third phase; the commit/acknowledge phase. This does mean that it takes four round trips to provide a linear transaction, but so long as you don’t need to many atomic transactions in your application, it works.
Triggers are the next improvement, and remain a work in progress with a warning of changes to come in Cassandra 2.1. However, the triggers currently rely on logged batches to implement a flexible, atomic, eventually consistent mechanism for reacting to – and augmenting – write operations. The CQL enhancements add cursors and improved index support. There’s support for the new triggers, and some support for the new lightweight transactions. This support is exposed through the support of the IF keyword in INSERT, UPDATE and DELETE statements. The extra support for indexes lets you use columns for secondary indexes that are already used as primary key columns. Other improvements include
Source code, documentation, and related resources are available on the Apache Cassandra site.
Paxos consensus protocol
Related ArticlesCassandra 1.0 with Increased Performance
To be informed about new articles on I Programmer, install the I Programmer Toolbar, subscribe to the RSS feed, follow us on, Twitter, Facebook, Google+ or Linkedin, or sign up for our weekly newsletter.
Comments
or email your comment to: comments@i-programmer.info

|
|||
| Last Updated ( Tuesday, 10 September 2013 ) |