Headless Chrome and the Puppeteer Library for Scraping and Testing the Web
Written by Nikos Vaggalis
Wednesday, 29 November 2017
With the advent of Single Page Applications, scraping pages for information as well as running automated user interaction tests has become much harder due to its highly dynamic nature. The solution? Headless Chrome and the Puppeteer library.
While there's always been Selenium, PhantomJS and others, and despite headless Chrome and Puppeteer arriving late to the party, they make for valuable additions to the team of web testing automation tools, which allow developers to simulate interaction of real users with a web site or application.
Headless Chrome is able to run without Puppeteer, as it can be programmatically controlled through the Chrome DevTools Protocol, typically invoked by attaching to a remotely running Chrome instance:
Subsequently loading the protocol's sideckick module 'chrome-remote-interface' which provides a simple abstraction of commands and notifications using a straightforward JavaScript API, one can execute JavaScript scripts under a local Node.js installation.
From the official documentation, here is an example that navigates to https://example.com and saves a screenshot as example.png::
But since there's 'chrome-remote-interface' already, what does Puppeteer do differently? Puppeteer offers a higher level API to the CDP than the one made available by 'chrome-remote-interface'.
As Paul Irish explains:
(with CDP) it's kind of horrifying that it takes ~75 LOC to take a fullpage screenshot with the protocol. I felt uncomfortable asking all developers to engage with the browser at that layer.
Instead of those 75 lines, with Puppeteer that should be more like:
This is more reasonable for all developers who want to write an automation script.
It's even more developer friendly than that as it also packs an internal headless Chrome instance so you don't have to explicitly call it as we've seen above.
So let's see Puppeteer in action in scraping all available image elements from a web page:
What happens when running 'node smadeseek1.js' is:
A headless Chrome instance is launched
Wait until the contents of the URL are loaded by hooking to the document.onload event
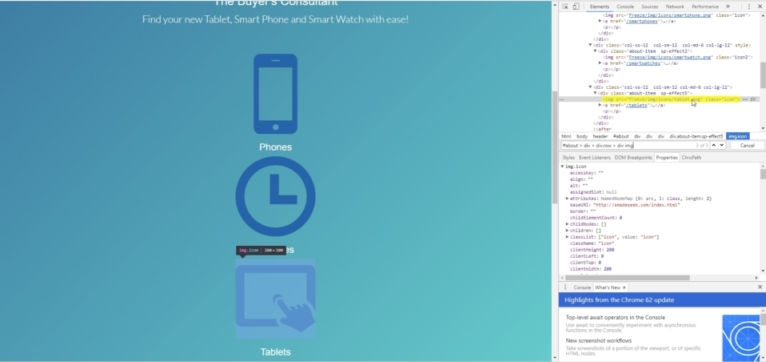
Call page.$$eval which wraps document.querySelectorAll passing to it the CSS selector for the element we are after, that is "#about > div > div.row > div img"
Iterate over the array we named as 'images' which contains all matching the CSS selector 'img' elements and retrieve their 'src' properties.
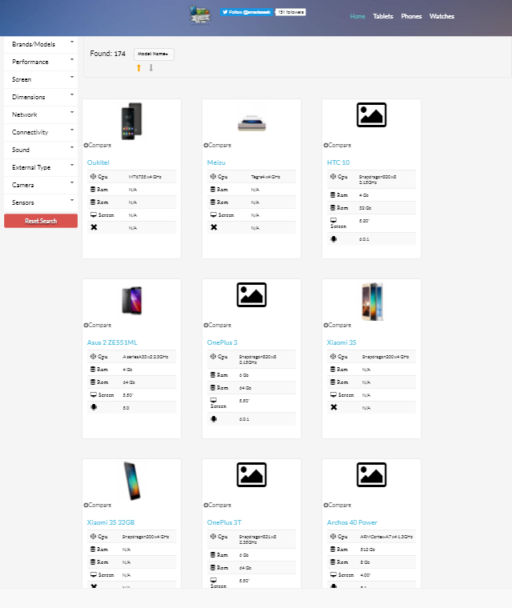
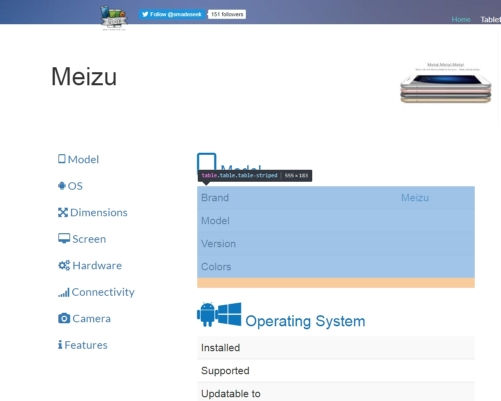
For example, let's go to www.smadeseek.com and load a list of all smartphones availability.Then programmaticaly click on the img element of the second displayed device to bring up its detailed specifications page. From there we can access the innerHTML of the first table element:
//smadeseek2.js
const puppeteer = require("puppeteer");
const url = "http://smadeseek.com/smartphones"; const imgSelector = "#contentx > div > div img"; const tableSelector = "#masthead";
const tableSelector2 = "#masthead > div > div:nth-child(2) > div > div > div.col-md-6.col-sm-6 > table:nth-child(2)";
There's just one caveat. Since CDP only works with Chromium, Chrome and other Blink-based browsers, so does Puppeteer. If you require more than that, then sticking to Selenium and its WebDriver API still remains the best option..
Its Xmas and Xmas means Donald Knuth putting on his flamboyant Xmas top and talking to us about something that most of us know nothing about? Of course not. This year it's all about the Kni [ ... ]
Announced this week at CES 2026, the SMART Brick is designed to power a new LEGO ecosystem called SMART Play. Will this be user-programmable and provide a replacement for the Mindstorms range of robot [ ... ]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}