| SQL Workshop - Removing Duplicate Rows |
| Written by Nikos Vaggalis | ||||||||||||||||||||||||||||||||||||||||||||||||
| Thursday, 19 February 2015 | ||||||||||||||||||||||||||||||||||||||||||||||||
|
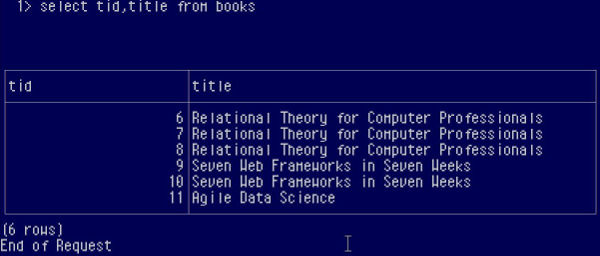
Let’s say that we have a heap table without keys, solely used for dumping raw data into. That data at some point is filtered and cleaned up for further use. As time passes and data accumulates, duplicate rows creep in causing all sorts of issues. So, using SQL, how do we remove the duplicates but keep the one row necessary? A Pure SQL ApproachWhile there are ways of writing a program in a host language which would procedurally loop over the rows keeping just the one occurrence, it is much more direct using pure SQL, although somewhat of a challenge. We will see how this is done and also learn about correlated subqueries, the ANY operator and tids along the way. First of all, let’s see what our data looks like:
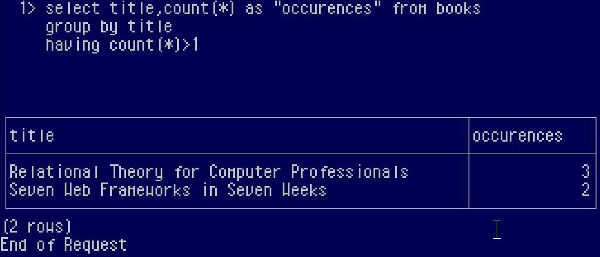
Let’s begin by discovering how many duplicate rows there actually are:
To do this, we group the rows by title, (if we wanted to be absolutely accurate and find the exact duplicates we would have to group on all columns, but we omit this step for brevity and just check for repetitions of title), and check for how many duplicates per group there are. So if we group the data by title we discover that there are 3 occurrences of the title “Relational theory for Computer Professionals” and 2 of the title “Seven Web Frameworks in Seven Weeks” . Note that “Agile Data Science” doesn’t come up in the result set as its having count returns 1 which means it hasn't been duplicated. We just found how many duplicates per group there are, but how do we delete all but one, thus cleaning up our table? The problem is that there are no keys that uniquely identify each row. Or are there?
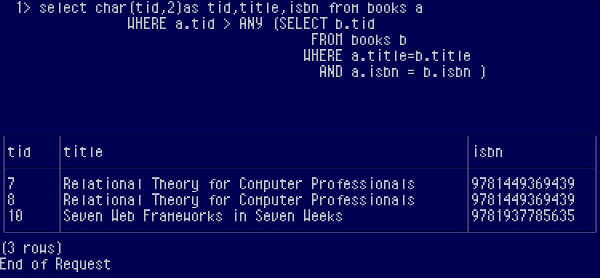
Using the TIDLet’s welcome the TID or Tuple (row) ID. Internally each row is stamped with a unique id used by the DBMS for its own purposes but is exposed to the outer world with the TID. The TID, however, is not a constant value and changes dynamically upon operations on the table, so it cannot be used to identify the rows in the long term, though it is sufficient for our purposes. Note that it is called TID in the Ingres jargon other DBMSs’ will name it similarly. So we see that each row has a number which acts as something of an auto-increment Primary Key, uniquely identifying each row. Getting hold of this key allows us to identify the candidates for deletion:
Let’s break that expression down. We do a self-join, joining the table with itself as seen from the outer and sub queries. For each row of the outer query we run the inner sub query which means that for a row with title “Relational theory for Computer Professionals” the sub query will run multiple times. This is called a correlated sub query. Then the ANY operator will check for, well, any row in which the tid is higher than those coming up through the sub query. In other words, the goal is to find the duplicate rows with the highest tid. Now, if you replace the term tid with the term primary key, our intention becomes clear. We go through several passes for each row: For a row of the outer query with title “Relational theory for Computer Professionals” we find those rows that have the same title (and ISBN, included for demonstration purposes, but again if we need to be completely accurate all columns should be included) in the sub query, thus for row with tid 6 of the outer query the sub query finds 3 rows with the same title and ISBN:
Now it’s time for ANY and tid to step in checking the outer query’s tid against the tids resulting from within the sub query.
Next outer query row (tid 7)
Next outer query row (tid 8)
We keep the rows that answer YES, which are row tid 7 and 8 which become our candidates for deletion, with only row tid 6 surviving the deletion. The same process will take place for the next titles as well.
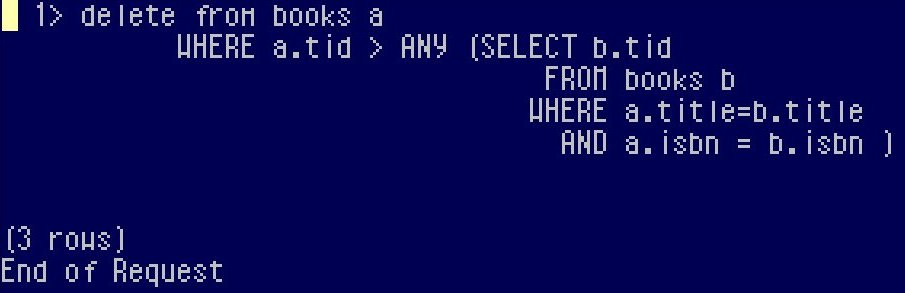
Easy DeletionThe deletion then is easy - just replace the Select with Delete:
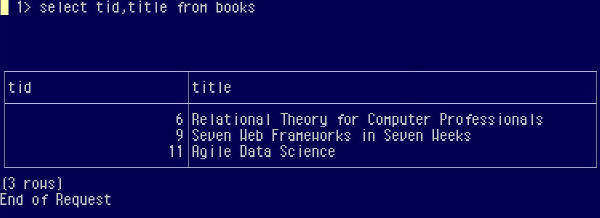
At the end, the rows that survive deletion are those with the lower tid than their counterparts:
So we have seen that deletion of duplicates can be done within SQL itself. It might be worth considering this pure SQL approach rather than the procedural logic of a program written in a host language the next time a situation like this occurs. It is amazing what a relational approach can do without any help from imperative programming.
Other SQL WorkshopsSQL Workshop - Selecting columns without including a non-aggregate column in the group by clause SQL Workshop - Subselects And Join To be informed about new articles on I Programmer, install the I Programmer Toolbar, subscribe to the RSS feed, follow us on, Twitter, Facebook, Google+ or Linkedin, or sign up for our weekly newsletter. |
||||||||||||||||||||||||||||||||||||||||||||||||
| Last Updated ( Thursday, 19 February 2015 ) |