| Virtual Memory |
| Written by Harry Fairhead | |||
| Sunday, 20 November 2022 | |||
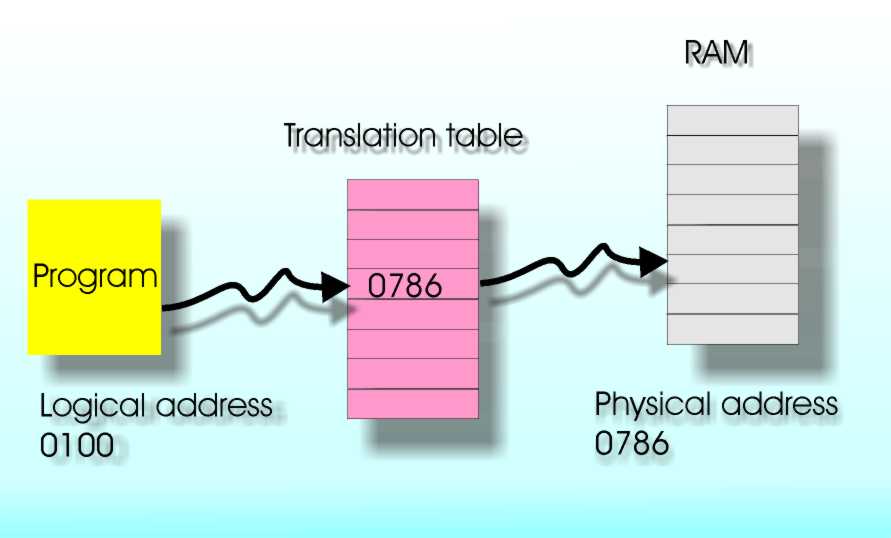
Page 1 of 2 Virtual memory is a way of pretending that your computer has more memory than it really has. But like all good things it comes at a cost. Virtual memory is an example of trading speed for storage. Virtual memory is not an idea that occurs early in the development of computing - it isn't a fundamental computing idea. It is more something that you need to make computing practical and so you could consider it a detail of implementation. However it is based on some fundamental computing principles and it is used by all but the simplest computers. It also explains how you can have more programs running than you have memory installed to support them. As a programmer you need to understand the effect your program's demand for memory has on the machine and the running time of everything using it. Virtual memory is that it is something that only makes sense after you have quite a lot of very specific technology implemented and working. In particular, you need to have a range of different types of memory components offering different performance at different costs. Usually a computer has a relatively small amount of fast storage which is directly coupled to the CPU and a much larger amount of storage that is slower to access. This split is usually referred to as primary and secondary storage. You don't start thinking about inventing virtual memory until you have build a machine that has both types of memory and where the secondary memory is reasonably fast and cheap. Virtual memory seems to have been thought up by Tom Kilburn around 1960 while working on the Manchester series of computers – but I’m sure someone will tell me that it was invented much earlier by someone else. Overlay programmingBefore the days of virtual memory it became clear that we had to find a way to run programs that were larger than the memory available. This gave rise to "overlay" programming an art that has more-or-less died out. Even in the early days of computing the cost of memory was high compared to the cost of slower disk or drum based storage. So there you are sitting in front of your new computer and it has a main memory of around 4Kbytes say and a disk of a few 100Kbytes. At first the programs that you write are easy to fit into the 4Kbytes and larger systems can be built as a “suite” of programs which can be run on demand. Sooner or later, though, you are going to reach the point where the programs that you really want to run are larger than 4Kbytes and the obvious solution is to break them into chunks smaller than 4KBytes and arrange for the modules to be loaded into memory as needed. Notice that you can’t just load the program modules from disk you also have to arrange to save modules that have done some work so that they can be restored at the point that they were interrupted. This is called “overlay” programming and it was the standard way of running a large program on a small machine for many years. It worked but its big disadvantage was that its effectiveness depended on the skill of the programmer to break the application into non-interacting chunks. You also had to arrange for the operating system to load and unload chunks of code and this had to be specified as part of the program. It was a very manual system and very prone to errors and inefficiencies. We needed something better. Logical and physical address spacesOverlay programming is a software system but the general idea of loading only what is needed when it is needed can automated with the help of some additional hardware. First we need to recognize the fact that from the programmer’s point of view what matters is the machine’s “address space”. This is the range of addresses that might be used in a program. Since the early days of computing a machine’s address space hasn’t actually coincided with the RAM available on any given machine – i.e. some addresses may be empty. For example, a modern machine typically has a 36-bit address space, i.e. 64Gbytes. (The actual addressing details of the usually complicated so this is more like a theoretical estimate.) Despite the fact that RAM is cheap, most machines don’t have sufficient RAM to fill their address space and so most of it is empty. It turns out to be very helpful to separate the address a programmer uses to specify a memory location, the “logical address”, from the actual “physical address” that some RAM is wired to respond to. At first this seems like a crazy idea! Why complicate matters in this way? It turns out to be a key idea in the design of a modern computer. It is a good idea to use logical and physical addressing because you can arrange a mapping between the two to pretend that you actually have more memory than is available. You can think of it as a trick where any logical address that a programmer attempts to use is automatically mapped to a physical address where the memory actually lives. You may have only 1GBytes of physical memory in your machine but by arranging the mapping of logical to physical memory it can appear to be anywhere in the 64Gbyte logical address space. It’s a bit like having memory that can slide about to fill any hole in the address space you care to use. Translation tablesSounds good but how is the mapping from logical to physical addresses carried out? The simple answer is that it is done by a lookup table implemented in hardware. A table in RAM is used to store the physical location of any logical address you care to use. Obviously you can’t have a lookup table that stores the location of every logical address – this would use all of the physical memory up just keeping track of where everything is! To make it work memory has to be divided up into pages – the x86 typically uses 4KByte pages for example (but this can be varied). The physical address of the start of each 4KByte page is stored in a table and all logical addresses within a 4KByte region are mapped to the same 4KByte physical page. So now the table, the page table, stored in memory controls the position of 4KByte pages of physical RAM in the logical address space. The operating system has to work out how to set the page table up so that an application program can be loaded into memory correctly and runs correctly but this is not a huge problem.
Logical to physical addresses via the translation table

<ASIN:0131429388> <ASIN:0131453483> |
|||
| Last Updated ( Sunday, 20 November 2022 ) |