This may seem like a very complicated way of thinking about a very simple code, but it opens up the possibility of constructing more advanced codes. For example, the key to the parity checking code is that every valid code is surrounded by invalid codes at one unit’s distance and this is why one-bit errors are detected. To detect two-bit errors all we need to do is increase the radius of the "sphere" of invalid codes from one unit to two units.
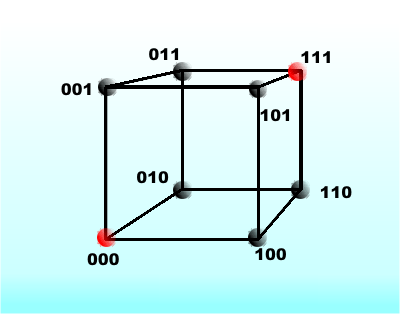
In the three-bit code case this leaves us with only two valid codes, 000 and 111. Anything else is an invalid code that was generated by changing one or two bits from the original code words. Notice that 000 and 111 are three units away from each other. Now we have a code that can detect a one- or two-bit error with certainty, but, of course, it can’t detect a three-bit error!
A two-bit error detecting code
Problems start to happen when you increase the number of bits in the code. If the code has n bits then it labels the 2n corners of an n-dimensional hypercube. All we have to do to make a code that detects m-bit errors is to surround each valid code word with invalid codes out to a distance of m units.
Although it might seem like strange terminology, you can refer to the surrounding group of invalid codes as a “sphere of radius m” - after all they are all the same distance away from the valid center code. It is also clear that error detection carries an increasing overhead. A three-bit code that detects one-bit errors has four valid codes and four invalid codes. A three-bit code that detects two-bit errors has only two valid codes and six invalid ones.
Error detecting codes don’t carry information efficiently – you have to use more bits than strictly necessary for the information content. This is called “adding redundancy” and follows the general principle of information theory that in the presence of noise adding redundancy increases reliability.
.
Error correction
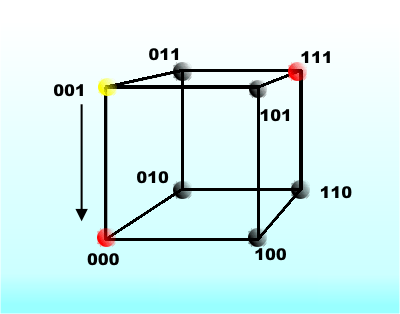
To make the small, but amazing, step from error detection to error correction we need to construct an error correction code, something that we have, in fact, already done! Consider the three-bit code that can detect up to two-bit errors. In this code the only valid words are 000 and 111. Now consider what it means if you retrieve 001. This is clearly an illegal code and so an error has occurred, but if you assume that only a one-bit error has occurred then it is also obvious that the true code word was 000.
Why? Because the only valid code word within 1 unit’s distance of 001 is 000. To get to 111 you have to change two bits. In other words, you pick the valid code closest to the invalid code you have received.
The yellow incorrect code word is closest to 000
What this means is that a code that has invalid words surrounding it, forming a sphere of radius two, can detect errors in up to two bits and can correct one-bit errors. The general principle isn’t difficult to see. Create a code in which each valid code word is surrounded by a sphere of radius m and you can detect up to m-bit errors and correct m-1 bit errors. The correct algorithm is simply to assign any incorrect code to the closest correct code.
Real codes
Of course this isn’t how error detecting/correcting codes are implemented in practice! It is the theory but making it work turns out to be much more difficult. The additional problems are many. For example, to have a high probability of dealing with errors you have to use a large number of bits. You can make any unreliable storage or transmission medium as reliable as you like by throwing enough bits at it. This means that you might have to use a huge table of valid and invalid code words, which is just not practical.
In addition, whatever code you use it generally has to be quick to implement. For example, if an error occurs on a CD or DVD then the electronics corrects it in real time so that the data flow is uninterrupted. All this means that real codes have to be simple and regular.
There is also the small problem of burst errors. Until now we have been assuming that the probability of a bit being affected by noise is the same no matter where it is in the data word. In practice noise tends to come in bursts that affect a group of bits. What we really want our codes to do is protect against burst errors of m bits in a row rather than m bits anywhere in the word. Such burst error correcting codes are more efficient but how to create them is a difficult problem.
For example, if you want to use a code that can detect a burst error of b bits then you can make use of a Cyclic Redundancy Checksum (CRC) of b additional bits. The CRC is computed in a simple way as a function of the data bits, and checking the resulting data word is equally simple, but the theory of how you arrive at a particular CRC computation is very advanced and to understand it would take us into mathematical areas such as Galois theory, linear spaces and so on.
The same sort of theory can be extended to create error-correcting codes based on CRC computations, but if you want to learn more about error detection and correction codes then you have to find out first about modern mathematics.
If you want a comprehensive and mathematical approach then Error-Correcting Codes by W. Wesley Peterson is recommended.
For a more general and short but still mathematical introduction try: A First Course in Coding Theory by Raymond Hill
See the sidebar for links to both books.
Summary
If you are prepared to use more bits than are necessary to send a message, you can arrange for errors to be detected and even corrected.
The first error detection scheme we encounter is usually parity. An extra bit is included with the data to make the data either have an odd number of ones or an even number of ones. If a single bit changes then the odd or even property is changed and the error can be detected.
A parity check can only detect a single bit error. Changing two bits returns the data to the original parity.
The Hamming distance between two items of data is simply the number of bits by which they differ.
Another way to look at the parity check is to notice that an error in a valid code word changes it into an invalid code word just one unit away.
This idea can be generalized to detect errors in more than one bit. If each valid code word is surrounded by invalid code words that differ by m bits, then we can detect errors that change up to m bits.
Error correction extends this idea so that the each invalid code is only within m bits of a single valid code. This single valid code is the only one that could have resulted in the invalid code by a change in m bits and hence we can correct the error by selecting it as the correct code.
In practice error detection and correction codes have to be fast and easy to use. The error has to be detectable and correctable by a simple computation, usually implemented in hardware.
To design codes of this type requires a lot of modern mathematical ideas.
A Programmers Guide To Theory
Now available as a paperback and ebook from Amazon.
Contents
What Is Computer Science? Part I What Is Computable?
Today, December 9th 2025, is the 119th anniversary of the birth of Grace Hopper. Her concern for teaching young people is why Computer Science Education Week and the Hour of Code, now the Hour of AI, [ ... ]
Angular 21 has been released with experimental support for Signal Forms, a developer preview of Angular Aria, and the ability to use Angular's MCP Server via AI Agents.