| Processor Design - RISC,CISC & ROPS |
| Written by Harry Fairhead | |||
| Friday, 23 March 2018 | |||
Page 1 of 2 When it comes to processor architecture we still don’t have a clear agreement on what sort of design philosophies should be followed. How do you make a faster general purpose processor? This is a question about architecture. Processor perfectionIf you want to start a really good argument among a group of hardware enthusiasts just mention the fact that such-and-such a processor is better then some other! When it comes to processor architecture we don’t even have a clear agreement on what sort of design philosophies should be followed to produce a good one. What we do have is a collection of techniques and approaches that all promise to deliver processor perfection. In the early days of computer design the big problem was simply that any sort of processor took so much electronics to build that the main concern was keeping things simple. Even when integrated circuits became possible it was still difficult to achieve the sort of component density needed to implement a complete processor on one chip. As a result the early microprocessors were very primitive even by the standards of computer design of the day. This is the reason that they were called "microcontrollers" or "microprocessors" - even the idea they could be used to create a small computer system was thought to be slightly silly. The very first processor design philosophy was just the simple idea that more is better. Designers attempted to make a processor do more at each step and tried to make each step take less and less time. Most processors are “synchronous” – that is they use a clock to time when instructions occur. There are asynchronous designs were different things occur at different times and rates across the processor but so far these are mostly experimental systems. At its simplest, a synchronous processor carries out one instruction (or at least the same number of instructions) per clock cycle. Hence you can get more processor power simply by increasing the clock frequency. Initially processors operated at 1MHz (i.e. 1 million pulses per second) but over the years clock rates have shot up to 3-4GHz (i.e. 1 thousand million pulses per second). What this means is if nothing else had changed the processor we use today would be 1000 times faster than the ones we used back in the 1980s. It is worth thinking about these figures for a moment. The electronics becomes more difficult to design as the frequency it handles increases. The problems are that much above 1MHz the signals start to radiate as radio waves. For example 1MHz is classed as medium frequency, 1GHz is UHF and used for TV signals, 2GHz is the frequency used by WiFi and microwave ovens. So building a computer at 2GHz and above gets increasingly difficult as the frequency goes up. It is still true that increasing the clock rate is one of the most effective way of speeding things up – but it’s not the most interesting and recently the effort to increase clock rate has run out of steam so much so that we can no longer rely on simple clock speed increases to keep our bloated software running faster each year. CISC and RISCSo the really important question is: How can you make a processor faster without increasing the clock speed? The most obvious way is to increase the amount done per clock pulse. This is so obvious that it’s what has happened to processors without anyone really working out that this is the best thing to do! You could say that
Over time processors supported more and more instructions that did more and more. For example, early processors only supported addition and subtraction instructions and to multiply and divide you had to write a small program that implemented general arithmetic using nothing but addition and subtraction. Of course today’s processors have special numerical hardware built into them that can do high precision arithmetic in a single operation. This is an example of each instruction doing more and implementing what used to be multiple instructions within one instruction. More, bigger, complex instructions make the processor do more per clock pulse. How could such an approach be wrong? Surely it must be better to have a powerful multiply instruction than have to create one from feeble addition instructions? Well to a great extent the obviousness of this argument is based on a misunderstanding of what computers do. Back in the early 1970s John Cocke at the IBM research labs analysed exactly what instructions a processor used most often. He discovered that of the, say, 200 instructions a processor might support, only 10 or so were used at all often. In fact these 10 instructions accounted for over two thirds of the processor’s time. Later this became enshrined in the 80/20 rule – 80% of the work is done by 20% of the instructions. What this implied was that by making these core instructions work as fast as possible the processor would be greatly speeded up. In fact given that only 10 or so simple instructions were really used why bother worrying about the rest! This gave rise to the idea of a RISC, or Reduced Instruction Set Computer, which implemented a very small set of instructions as efficiently as possible. Compared to a CISC – Complex Instruction Set Computer – a RISC machine might seem a silly idea.
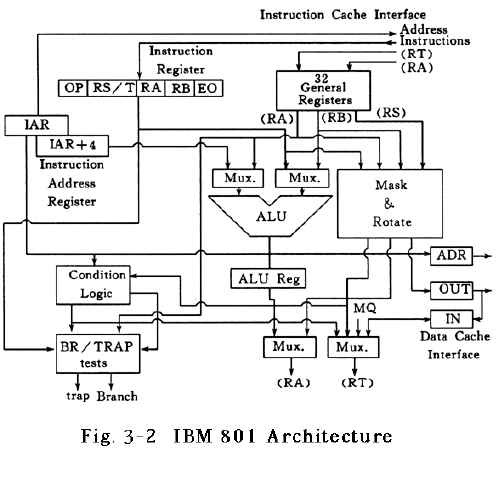
The first IBM RISC Processor
The simple instructions did very little but they could be executed at a very fast rate! This is almost the basic principle of a computer, which does very little very very quickly! The idea is a little more subtle than it is usually painted. John Cocke's idea was really to not increase the complexity of a machine unless the instruction was used often enough to provide a payback. That is, it isn't that short simple instructions are better by some principle it is more that you should tailor the instruction set of a computer so that the instructions most use are the best implemented. Who Is the User?The other big realization that Cocke's work brought to the attention of machine designers was the idea that the user of a machine instruction set wasn't the programmer but the compiler. Back in the early days assembly language programmers hand crafted code. When they needed to perform a multiplication on a machine that only performed additions in hardware then it was a lot of extra work to either write or borrow a multiplication routine. Of course programmers wanted complex instructions they made programming in machine code easier. Programmers prefer CISC. Later of course programmers moved away from machine code to high level languages and to an extent their involvement with the instruction set of a computer became less. At most they might admire a machine's design almost in the abstract but when it came to generating machine code it was the compiler that was all important. The fact is that compiler writers simply didn't make use of the complex instructions on offer. They generally used a small set of instructions that were enough to get the job done. This simplified the design of the code generation portion of the compiler. As the technology advanced the prime consumer of machine instruction sets and hence the determining factor in what was a good design was the compiler - and compilers used a small simple subset of the instructions that might be available. Compilers prefer RISC. Why CISC At All?If RISC is such a good idea why do we still use so many CISC x86 processors in desktop machines and servers? For a time the Mac used a RISC processor – the PowerPC – but even here CISC triumphed with Apple eventually switching to Intel processors. Sun also offered Sparc based RISC machines, mainly to scientists and engineers, but eventually lost the struggle and was taken over by Oracle, mainly for its software assets. RISC suddenly became important with the introduction of the smart phone. The reason is simply that RISC processors consume less power and hence they are ideal for mobile, battery-driven, devices. Even if they don't have the computational power of their CISC relations they are a good match for the task. At long last RISC processors like the ARM family have made an impact on the wider world. So much so confidence has grown about using them in servers and desktop machines. As the power of Window lessens and the power of a typical RISC chip increases things are changing. In the future you may have to visit a museum to see a CISC processor. There is a sense in which this is already true, <ASIN:0070570647> <ASIN:0123705916> <ASIN:0471736171> |
|||
| Last Updated ( Friday, 23 March 2018 ) |