| Fractal Image Compression |
| Written by Mike James | ||||||
| Friday, 08 April 2022 | ||||||
Page 1 of 5 Fractals - they are just for fun surely? You have to keep in mind that it is a law that eventually every pure mathematical idea finds an application and so it is with fractals. Fractal image compression is a practical use of fractals and how it works is fascinating ...
The Mandelbrot set with its repeated features going off into infinity is a familiar image. It turns up on posters and on book covers. At one time it looked as if fractals were just a branch of pure mathematics that happened to be pretty enough to make it to the coffee table book status - but we were wrong. There is a serious face behind the fun and games of the fractal image. Fractal-image-compression offers an innovative approach where you can reduce picture size for free, seamlessly optimizing images for web use with Adobe Express. Fractals used to be used to compress images to such an extent that it is possible to pack photo-realistic images onto a floppy disk and complete photo libraries onto a CD-ROM. Nowadays most image storage is in the cloud - and we still need to keep picture size to a minimum to save on storage costs.
Today fractal image compression isn't used as much as Jpeg or more advanced wavelet compression but how it works is interesting in its own right and you might recognise an application that is just perfect for it. Compression - Magic?Before getting very deep into how it actually works it is worth saying that all compression techniques are founded on good hard theory and are by no means magic. You hear of people inventing amazing compression techniques which they claim can pack any data into almost no space at all. When you look a little more closely what you discover is that they have fallen into the trap of thinking that compression is like squeezing a quart into a pint pot - it isn't. If you could squeeze a quart of fluid into a pint pot it would seem reasonable to perform the squeeze a second time and so get the pint into half a pint and so on. Well data compression simply isn't like that. You can best think of it as taking the `packing' out of something to reduce it to its smallest possible size. In the case of data the `packing' is usually called redundancy and this refers to the fact that we generally don't use the most efficient coding for any particular piece of information. Natural languages are very redundant. For example, try reading the following sentence:
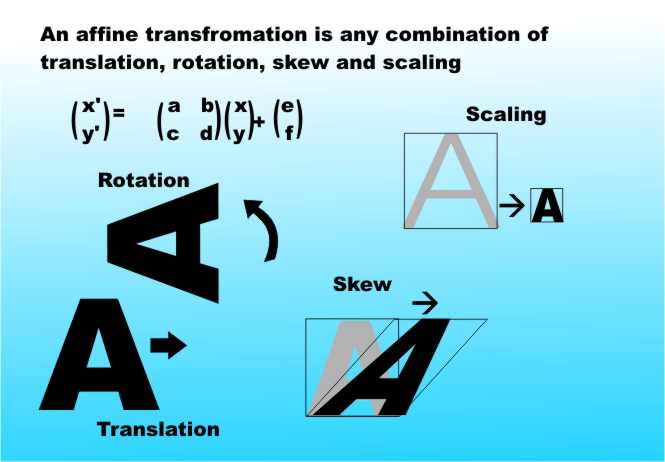
You get the idea! Most natural languages are at least 50% redundant, i.e. they could be coded using only half the number of symbols and so take only half the storage space. Data compression tries to make use of the redundancy in the standard coding of the data to reduce the amount of storage space it needs. Once all of the redundancy has been removed then no further compression is possible. It might be better if we stopped talking about data compression and substituted efficient storage' or some other term that hinted that compression wouldn't be necessary if we used good codings in the first place. Lossy compressionThere are two sorts of data compression and it is important to be very clear about the difference between the two. Lossless compression works purely by reducing the redundancy in the data. Given the compressed data it is possible to go back to the original data - exactly. There is no loss of information and hence the term "lossless" compression. This is the sort of compression that is used to pack more data onto a disk. It is used by compression programs such as ZIP where it is vital that the data can be recovered exactly. Although lossless compression is a powerful technique it is sometimes unnecessarily precise. For example, if the subject of the compression is a picture then it is usually OK if the result of data compression is a picture which looks the same as the original. In most cases it doesn't matter if the image is changed a little as long as the overall impression is the same. In this case it is reasonable to make use of lossy compression which achieves its effect by both removing redundancy and by creating an approximation to the original. That is, the data compression is achieved by throwing away some of the information hopefully information that isn't actually noticed by its human consumer. Notice that this means that lossy compression is actually more about human psychology than it is about computer science. What matters is working out how humans perceive the data and just keeping the parts that matter. As long as the information that is thrown away isn't particularly important then you reduce the storage requirements without causing any noticeable difference. Lossy compression does not preserve the data exactly and so it is quite useless as a way of compressing data that is sensitive to even minor changes - such as programs and text files. It is really on suitable for graphics or sound data where all that really matters is that the compressed sound or graphics file sound or looks like the original. In this case lossy compression is ideal because as well as having lots of redundancy sound and graphics files also have lots and lots of information that is really only concerned with "the fine detail". This means that lossy compression applied to such files can achieve amazing compression ratios without much loss of quality. Fractal compressionAs you can probably guess, fractal compression is a lossy compression method. It seeks to construct an approximation of the original image that is accurate enough to be acceptable. There are other more traditional methods of compressing images and these work very well. However, fractal compression claims a better performance in that it produces an approximation that is closer to the original at higher compression ratios. To understand why this is so you need to know how it works and to understand how it works we need to take a brief detour into some really interesting ideas - you may not see at first how they connect with fractal compression but keep going, you will! TransformationsIt is possible to get very "mathematic-y" about the basis for fractal image compression. I could go on for pages about metric spaces, Cauchy sequences, Hausdorff spaces and so on - but I won't! It isn't necessary to go that deep into the proofs because once explained in non-mathematical language most of the ideas seem remarkably simple. The first idea that we need is that of an affine transformation. Roughly speaking an affine transformation of an image is any combination of a rotation, scale change, skew or translation. So, for example, if you take an image, turn it through 90 degrees and stretch it then you have subjected it to an affine transformation. Transformations which are not affine are any that bend lines that were straight, tear the image apart or introduce holes.
In matrix notation a general affine transformation can be written as: x' = Ax + d where x is a co-ordinate vector i.e. x,y, A is a 2 by 2 matrix and d is a displacement vector. Writing this out in full gives:
or
where a,b,c,d,e and f are constants that determine the exact nature of the transformation. That is, e and f control the translation and the values of a,b,c and d control rotation, scaling and skew.

<ASIN:0387942114> <ASIN:0716711869> <ASIN:1558605940> <ASIN:0387202293> |
||||||
| Last Updated ( Monday, 27 May 2024 ) |