| Learning to Sound like a Fender |
| Written by Harry Fairhead | |||
| Tuesday, 06 November 2018 | |||
|
Bassman 56F vacuum tube amplifier, that is. Yes, neural networks go where no network has gone before. It is now officially amazing what you can think up for a neural network to do. We really don't need to get into an argument about audiophile tendencies to agree that classic vacuum tube amplifiers sound different. It's probably not that they are so good, more that they are bad in the right sort of way. If you want to sound like them what's the best way to do the job? You could build the hardware, as so many do at great expense and bother. Let's face it, vacuum tubes were never easy to use and putting a finger in the wrong place was a shocking experience. The most obvious thing to do is model the response, either by building a simulator to match the output characteristics or by analyzing the circuit and implementing some digital filters to do the job. However, the complex non-linear dynamics of a typical tube circuit is difficult to model. So why not get a neural network to learn how it sounds?
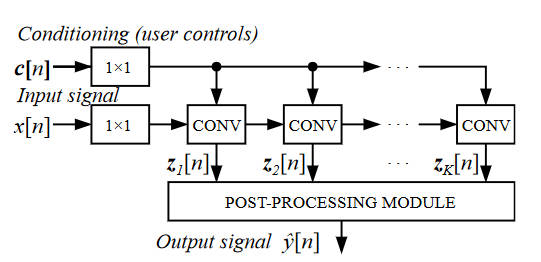
Inside a Fender Bassman 56F Credit Technical University Berlin. All we need is the transfer function, which changes the input raw signal into the output that sounds like the amp. This is something that a neural network should be able to learn. This is what Eero-Pekka Damskagg, Lauri Juvela, Etienne Thuillier, and Vesa Valimaki at Aalto University Finland decided to try. The network was based on the WaveNet model with modifications:
The network was trained to predict the current output sample given a set of past samples. The training data was, almost ironically, genenerated by a SPICE model of the Fender amp. Of course the SPICE model couldn't generate signals in real time. So did it work? Can you reduce some hot triode tubes to a set of neural network coefficients? It seems you can.
So you probably don't need expensive tubes to get the real sounds. It seems almost a shame. I wonder if they turned the coefficients of the network up to eleven?
More InformationDeep Learning for Tube Amplifier Emulation Related ArticlesAI Plays The Instrument From The Music The World's Ugliest Music - More than Random How the Music Flows from Place to Place To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Twitter, Facebook or Linkedin. 
<ASIN:0976982250> |
|||
| Last Updated ( Tuesday, 06 November 2018 ) |