| New Open Source Semantic Engine |
| Tuesday, 07 September 2010 | |||
|
You may not know that you need a semantic engine but if you are planning to do any advanced web development using AI or any clever technique you probably do. The new fise engine from Nuxeo is an open source HTTP server that can be used locally as well as hosted in the cloud. 
A semantic engine extracts the meaning of a document to organize it as partially structured knowledge. For example, you can submit a batch of news stories to a semantic engine and get back a tree categorisation according to the subjects they deal with.
Current semantic engines can typically:
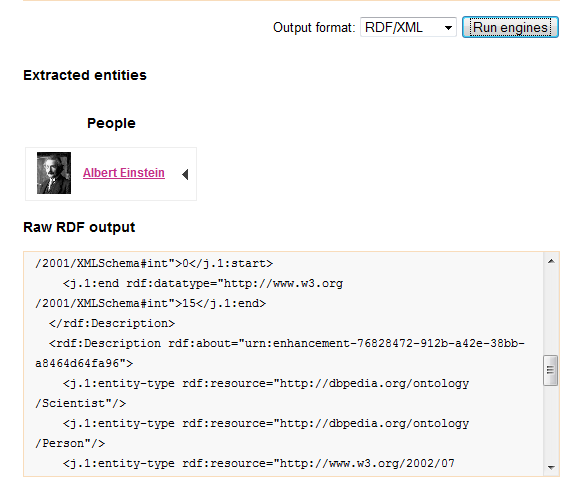
While there have been web-based engines such as Open Calais, Zemanta and Evri the new fise engine from Nuxeo is an open source HTTP server that can be used locally as well as hosted in the cloud. What this mean is that, if necessary you can keep your sensitive data in-house and still submit it to a semantic engine for analysis. If you want to try it out without having to download and host the code then there is a demo site provided. Fise has a Rest interface and looks fairly easy to use. You can submit a document and get back the analysis in a range of forms including a SPARQL query interface. To try it out in in a browser (at the time of writing IE doesn't seem to work) just navigate to http://fise.demo.nuxeo.com/engines. If you type in: "Albert Einstein was a clever man" and click Run engines and analysis will appear in the web page below your text input. A photo of Einstein shows that the engine detected the great man's name and then below an RDF format XML file gives you the semantic details. If you explore you will find that in the entity-type tags Einstein is identified as a Person->Scientist.
More complex documents produce more complex outputs, including a map showing the geographical relationships between people and places mentioned in the text. It isn't always perfect. For example, running our recent news item on Amazon's Kindle v Apple's IPad produced a map with Apple's headquarters indicated and the Amazon rain forest. Even so problems like this are fixable and the more the engine is used the better it gets! Internally it uses OpenNLP to identify entities, Apache Lucene to index and search entities and it calls on DBpedia to associate entities with locations. Clearly the task for most developers is to first learn how to use the API and then work out what to do with the RDF or whatever output format you choose. Making use of the semantic analysis is where the hard work now lies. But no matter how you look at it, having an open source semantic engine to try things out on is a gift.
The source code is available under the BSD license and is available from Google Code. More information can be found at: http://fise.demo.nuxeo.com/.
<ASIN:0596516495> <ASIN:0262133601> <ASIN:0131873210> <ASIN:0805303340> <ASIN:1420085921> |
|||
| Last Updated ( Thursday, 15 November 2012 ) |