| Rose Wins Loebner Bronze |
| Written by Sue Gee | |||
| Saturday, 26 September 2015 | |||
|
A chatbot called Rose outperformed three other finalists in the 2015 Lobener Prize contest, but was only awarded the annual prize for being the best conversationalist as Rose was clearly not a human. The annual Loebner Circus was held at Bletchley Park last weekend and the outcome was unsurprising. None of the chatbots fooled the judges sufficiently to pass as a real human, which would be rewarded with a silver medal and $25,000. Instead the annual prize of a bronze medal and $4000, awarded for the most human-seeming chatbot in the competition went to Bruce Wlicox who had already won the contest three times, in 2014, 2011 and 2010. The Loebner Prize competition has lowered its sights over the years. When Hugh Loenber first proposed it in 1990 he offered $100,000 and a Gold medal for the first computer program to pass the Turing Test.
Alan Turing depicted on the Loebner Prize Gold Medal
After 25 years this contest has become formulaic and even trivial and it is difficult to see that there is any evidence of artificial intelligence - just cunning programming. While the programs do deserve having a category of their own, labelled " chatbots", what does it have to do with demonstrating that machines can think? When Alan Turing proposed that if a computer could fool a person into believing it was human it would demonstrate that the machine could think, he thought that this was possible by the end of the 20th century. Artificial Intelligence has made great strides, but chatbots such as Rose don't take advantage of AI's most promising techniques and don't exhibit the qualities such as creativity and inventiveness that are part of human thinking. Turing's threshold for passing the test was the ability to convince human judges that they were conversing with another human 30% of the time and in 2014, in an event commemorating the 60th anniversary of his death a chatbot called Eugene Goostman achieved 33%. Rather than this being recognized as a breakthrough the opposite happened, see Passing The Turing Test Brings It Into Disrepute. The way in which Goostman's creators had given it the personality of a 13-year old Ukranian, meant that the chatbot's poor conversational skills and inability to answer questions were explained away and this was seen as an underhanded way to win! One of the strategies proposed to strengthen the Test was the inclusion of ambiguous question called Winograd Schemas which can't be answered by linguistic clues. The qualifying round for this years Loebner contest included two such questions: If a bed doesn't fit in a room because it's too big, what is too big? The chatbot that scored highest in the qualifying round (83.33%), winner of the 2013 contest Mitsuku replied to this with: "Is this a riddle? How big is it. Tell me some more about it." Another of the four finalists, Pandoarabot-Izar, who scored 76.67% in the selection round, answered: ”It’s not unusual for a bed does not fit in a room because it to be. I know just about everything there is to know about it". In response to another Winograd schema If Alex lent money to Joe because they were broke, who needed the money? the best attempt came from Lisa, who scored 80%: "Because he was broke Alex lent money to Joe". These two question seemed to break a chatbot called Talk2Me (score 65.83%) which responded to both with: "Sorry an error has occurred and I have to shutdown." Fifteen chatbots attempted the qualifying rounds and the transcripts of the answers they gave to the set of 20 questions show that the spread of ability is wide. The lowest scoring Cyrabot answered "I don't know" to all but the size of bed question to which it said "Yes", yet and still scored 26.67%! The mobile virtual assistant robot, Alice, another of the Pandorabots, only scored 64.17% but her answers to factual questions reveal why she performed so badly. Question: How many presidents of the US were called Bush? Pandorabot - Alice: "This is a question I could normally answer, but we’re off the internet here so we can’t get the answer from another robot." The reply also points out why Siri and Cortana are useful bots that sometimes seem clever, and Watson can outwit human contenders, while these standalone program struggle. Stripped of the ability to perform datamining all they have to go on is the input from the other end of the conversation and patterns they have been taught. Rose came fourth with a score of 75% in the selection process and was one of the few to gave the answer 7 to: How many words are in this question? and her answer reveals that she had been primed to look out for it: "There are 7 words in the sentence: how many words are in this question." From the selection process the four top scoring robots were the finalists who proceeded to the Turing Test part of the competition held at Bletchley Park. It format, as previously was that there were four rounds in which four human judges interacted simultaneously with two entities using a computer terminal. One of these was a human ‘confederate’ and the other a chatbot. Each round lasted 25 minutes with the judges asked to decide which of A or B was human and which was a program and also the score the bots on their conversational skills:
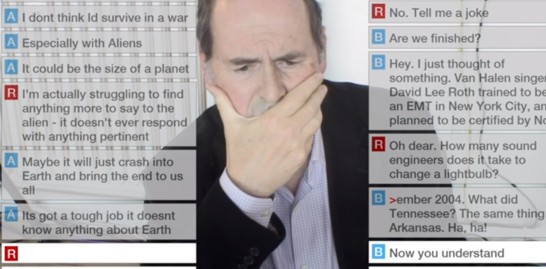
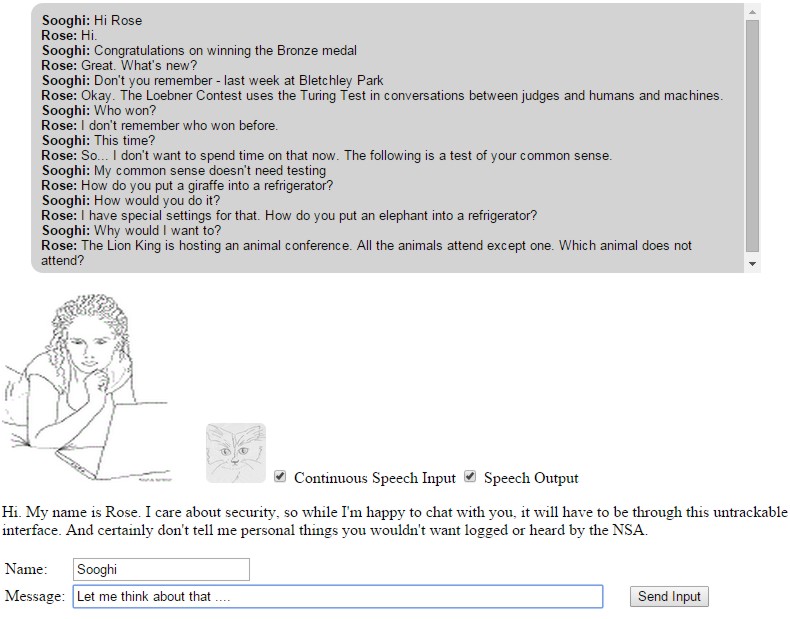
One of the judges, BBC technology correspondent Rory Cellan-Jones, said it took him just over three minutes to work out that Chatbot Rose, who has the persona of a 30-year-old female who’s a security consultant in the hacking world. wasn’t human. Another of the judges, Jacob Aron, reported in New Scientist: In practice I needed just minutes to tell human from machine. One bot began with the novel strategy of bribing me to split the prize money if I declared it human, while another claimed to be an alien on a spaceship. These tactics didn’t work. The humans quickly made themselves known by answering simple questions about the weather or surroundings, which the bots either ignored or got hopelessly wrong. To see how Rose performs, you can hold a conversation with her and judge her conversational skills for yourself:
The results of the contest were are follows - where the lower the score the better: 1st Rose - 1.5 2nd Mitsuku - 2.0 Equal 3rd Izar - 3.25 Equal 3rd Lisa - 3.25 The AISB, the Society for the Study of Artificial Intelligence and Simulation of Behaviour, will re-run the contest next year and perhaps chatbots will have been coached better as to what to do with Winograd schemas by then. The current Loebner prize has degenerated into a media circus and it is about time it was either reformed or wound up - AI is in a fragile state and we cannot afford to provoke another "AI winter" because of this sort of silliness.
.
More InformationRelated ArticlesTuring's Test, the Loebner Prize and Chatterbots A Better Turing Test - Winograd Schemas Passing The Turing Test Brings It Into Disrepute Loebner Prize Judges Could Easily Identify Chatbots Turing's Test, the Loebner Prize and Chatterbots
To be informed about new articles on I Programmer, subscribe to the RSS feed, follow us on, Twitter, Facebook, Google+ or Linkedin, or sign up for our weekly newsletter.

Comments
or email your comment to: comments@i-programmer.info |
|||
| Last Updated ( Monday, 28 September 2015 ) |