| Deep Learning Applied To Natural Language |
| Written by Sue Gee |
| Tuesday, 20 August 2013 |
|
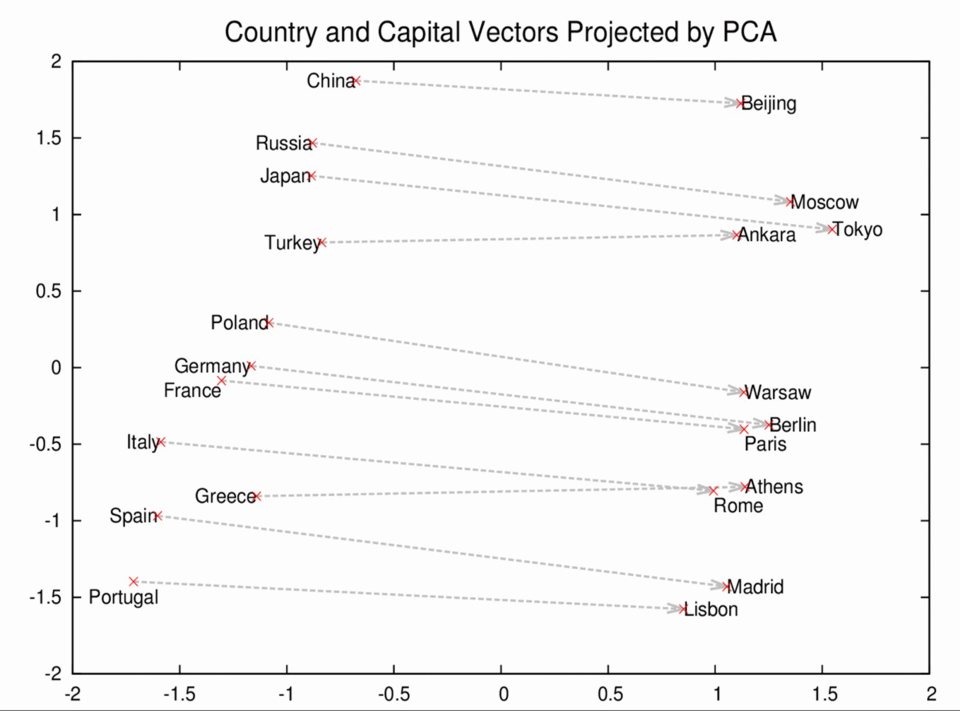
To promote research on how machine learning can apply to natural language problems, Google Knowledge is publishing an open source toolkit called Word2Vec that aims to learn the meaning behind words. Google is making great strides with neural network research and, having applied deep learning to photo search and speech regognition, the Google Knowledge team has turned its attention to natural language. In a blog post titled Learning the meaning behind words, Tomas Mikolov, Ilya Sutskever, and Quoc Le introduce Word2vec, a toolkit that has been made available as open soure, that can learn concepts by reading lots of news articles and without requiring human supervision. The blog explains that Word2vec uses distributed representations of text to capture similarities among concepts and provides this example that demonstrates its success in learning the concept of capital cities.
(click to enlarge)
This chart demonstrates that Word2vec understands that Paris and France are related the same way Berlin and Germany are (capital and country), and not the same way Madrid and Italy are. The model not only places similar countries next to each other, but also arranges their capital cities in parallel. The most interesting part is that we didn’t provide any supervised information before or during training. Many more patterns like this arise automatically in training. They suggest that there is a broad range of potential applications for this type of text representation tool, including knowledge representation and extraction; machine translation; question answering; conversational systems and for this reason they are open sourcing the code to enable researchers in machine learning, artificial intelligence, and natural language to create real-world applications. More details of the methodology encapsulated in Word2vec is available in a recent paper, Efficient Estimation of Word Representations in Vector Space by Googlers Tomas Mikolov, Kai Chen, Greg Corrado, and Jeff Dean in which they describe recent progress being made on the application of neural networks to understanding the human language. According to a post on Research at Google: By representing words as high dimensional vectors, they design and train models for learning the meaning of words in an unsupervised manner from large textual corpora. In doing so, they find that similar words arrange themselves near each other in this high-dimensional vector space, allowing for interesting results to arise from mathematical operations on the word representations. For example, this method allows one to solve simple analogies by performing arithmetic on the word vectors and examining the nearest words in the vector space.
More InformationLearning the meaning behind words Representing words as high dimensional vectors Efficient Estimation of Word Representations in Vector Space (pdf) Related ArticlesDeep Learning Researchers To Work For Google Deep Learning Finds Your Photos Google's Deep Learning - Speech Recognition A Neural Network Learns What A Face Is To be informed about new articles on I Programmer, install the I Programmer Toolbar, subscribe to the RSS feed, follow us on, Twitter, Facebook, Google+ or Linkedin, or sign up for our weekly newsletter.
Comments
or email your comment to: comments@i-programmer.info

|
| Last Updated ( Tuesday, 20 August 2013 ) |