| The Canvas Fingerprint - How? |
| Written by Ian Elliot | |||
| Tuesday, 29 July 2014 | |||
|
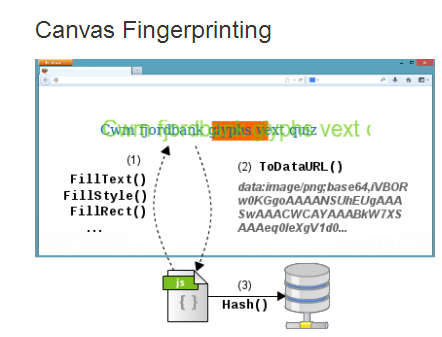
There is currently a lot of fuss going on about an additional method of fingerprinting browsers to track users as they move from one website to another. The technology is very simple but the real question is - how can it work well enough to be useful? Tracking users is something that the marketing internet needs to do to make sure that advertisers are kept happy. It is responsible for ads following you around. You view item x on one websites and you get lots of adverts offering to sell you other brands of item x on other websites that you visit. This is a feature that used to be implemented using cookies, but for lots of reasons users don't like cookies and so we have had to invent other methods of tracking users. The best known is fingerprinting browsers. Basically what you do is gather all of the data that a browser offers the server and use it like a hash to keep track of the user. The more data that is unique to a particular user's browser you can gather, then the more accurate the tracking is likely to be. The current fuss is that it has been discovered that a lot of sites are using Canvas fingerprinting to augment all of the other sources of fingerprinting data. The idea is that a JavaScript program draws something on a Canvas element and reads the bit pattern that results as the fingerprint. OK, simple enough to implement but you have to ask the question "why does the bit pattern vary enough to make it worth using?" When I use a drawing command that switches a particular pixel to a given RGB setting then, unless there is a hardware error, that pixel will have that RGB value and there is no variation in the bit pattern between browsers. However, if you use a GPU and a rendering command that specifies more generally what you want rather than exact pixel values, then there is scope for variation. For example, if you ask for a line to be drawn between two points using an anti-aliasing algorithm then exactly what each pixel is set to depends on the exact line drawing and anti-aliasing algorithm used. In this case the bit pattern can vary between browsers. The idea of using Canvas drawing via WebGL to identify browsers was invented back in 2012 in the paper: Pixel Perfect: Fingerprinting Canvas in HTML5 by Keaton Mowery and Hovav Shacham. To quote: "...using the operating system's font-rendering code for text means that browsers automatically display text in a way that is optimized for the display and consistent with the user's expectations." The way that text, say, is rendered to the Canvas depends on the display, the graphics hardware and the OS - but does this really provide the variability that a fingerprint needs? The paper goes on to say: "In 294 experiments on Amazon’s Mechanical Turk, we observed 116 unique fingerprint values, for a sample entropy of 5.73 bits. This is so So not enough for unique identification, but if you throw it together with other fingerprint data it helps. What is surprising is the idea that for about 300 users with similar systems the variations produces around 100 fingerprints - this is more than seems reasonable for any rendering algorithm. Are there really so many variation on the rendering of fonts and 3D graphics? The answer seems to be yes. For example, take a look at the difference images, taken from the original paper, for a single line of text rendered using text_arial:
And the same sort of variation can be seen in a 3D rendered image from systems grouped by GPU hardware:
The render involved 200 polygons and an applied texture. Overall the differences are more than one might expect from a naive consideration of hardware and rendering algorithms. This is such an effective method of fingerprinting that it was recently discovered many top websites are using it - mainly via the AddThis widget. Particularly embarrassing is the Canvas fingerprint presence on the White House web site - which is in contravention of its privacy policy.
More InformationThe Web never forgets: Persistent tracking mechanisms in the wild Pixel Perfect: Fingerprinting Canvas in HTML5 White House Website Includes Unique Non-Cookie Tracker, Conflicts With Privacy Policy Related ArticlesCat Photos - A Potential Security Risk? Print Me If You Dare - the Rise of Printer Malware Security by obscurity - a new theory
To be informed about new articles on I Programmer, install the I Programmer Toolbar, subscribe to the RSS feed, follow us on, Twitter, Facebook, Google+ or Linkedin, or sign up for our weekly newsletter.

Comments
or email your comment to: comments@i-programmer.info |
|||
| Last Updated ( Tuesday, 29 July 2014 ) |