| Cloudera Impala - Real-Time Query on Hadoop |
| Written by Kay Ewbank | |||
| Tuesday, 30 October 2012 | |||
|
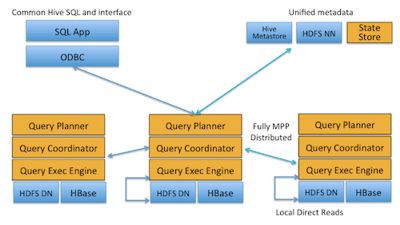
Cloudera has announced Implala, a real-time query engine for Apache Hadoop, which will work with data stored in a Hadoop Distributed File System, HDFS; and in HBase, the non-relational distributed database. Impala lets you query data using SQL SELECT, JOIN, and aggregate functions in real time. It uses the same metadata, SQL syntax (Hive SQL), ODBC driver and user interface (Hue Beeswax) as Apache Hive. The initial beta includes support for text files and SequenceFiles, and support for additional formats including Avro, RCFile, LZO text files, and Doug Cutting’s Trevni columnar format is planned for the production version.
Cloudera says that to avoid latency, Impala circumvents MapReduce to directly access the data through a specialized distributed query engine. The company says the result is order-of-magnitude faster performance than Hive, depending on the type of query and configuration. The advantages of this approach means that because of local processing on data nodes, network bottlenecks are avoided, and the data can be immediately queried with no delays for ETL. An Impala binary is now available in public beta as a VM. You can also review the source code and testing harness at Github. here: http://github.com/cloudera/impala. More InformationDownload Impala beta documentation Related Articles
Comments
or email your comment to: comments@i-programmer.info To be informed about new articles on I Programmer, install the I Programmer Toolbar, subscribe to the RSS feed, follow us on, Twitter, Facebook, Google+ or Linkedin, or sign up for our weekly newsletter. 
|
|||
| Last Updated ( Monday, 06 May 2013 ) |