| Covariance And Contravariance - A Simple Guide |
| Written by Mike James | ||||
| Friday, 20 November 2020 | ||||
Page 1 of 3 Programming, and computer science in particular, has a tendency to use other people's jargon. Often this makes things seem more difficult. You may have heard of covariance and contravariance and wondered what they were all about. If you want a simple explanation that applies to any computer language, here it is.
Covariance and contravariance are terms that are used in different ways in the theory of object-oriented programming and they sound advanced and difficult - but in fact the idea they they encapsulate is very, very simple. It is an idea that seems to originate in physics but in fact it is a more a mathematical concept. Let's find out.
Functions - the start of co and contraCovariance and contravariance occur all over mathematics - in vector spaces, differential geometry and so on. They derive from a very general idea based on observing what happens when you make a change - the result usually goes in the same direction as the change, i.e. it is covariant, but sometimes it goes in the other direction, i.e. it is contravariant. The most elementary example I can find of the co and contra behavior is the simple mathematical function. A function has an input and an output and these behave differently if you try to change them. For example, suppose you have the function:
then first lets see what happens to the function if we add a constant to x. You can think of this as defining a new function F(x)=f(x+a).
If you draw a graph of the function sin(x+a) you can easily see that the effect of the +a is to move the graph -a units. That is x is translated a units but the function is translated -a units. The function moves in the opposite direction to x and so we say that it is contravariant in x. The reason this happens is simply that if you add a to x then the function value that was at x i.e. f(x) is no longer produced when you enter x because this now produces f(x+a). The value that was produced by x i.e. f(x) is now produced when x is set to x-a as f(x-a+a) is just f(x) again. Thus shifting x by +a moves all the function values by -a.
Now consider adding a constant to the function y . You can see that y+a is given by sin(x)+a which moves the graph of the function up by a units. The function moves in the same direction as the constant and so we say it is covariant in y. The reason for this is much easier to see because the transformation is applied after the function i.e. F(x)=f(x)+a and the new function is just the old function moved up by a.
In general changes to the inputs of things tend to move the function in the opposite way and are contravariant but changes to the outputs move it in the say way and so they are covariant. This is where the idea comes from but it turns up with modifications in all sorts of places and it can seem much more sophisticated than this simple example - but in all cases it is contravariant if the change you make results in the opposite change in what you are considering and covariance if it results in the same change. Covariant and Contravariant VectorsNote: if you are not into physics skip to the next section. If you encounter the use of the contravariance and covariance in say physics or math then it might not be obvious that the difference is related to changes in inputs - contravariant or outputs - covariant, but if you dig deep enough you will find that this is exactly what it is. For example a contravariant vector is just a normal standard vector and when you change say the scale of the axes it changes in the opposite direction. The same rules work for a general transformation of the basis vectors but it is much easier to understand if you first restrict your attention to a simple change of scale. While we have introduced covariance and contravariance in terms of addition the same ideas work with any change you make. If you make a change to x and the change to y is the inverse change then we have contravariance. If it is the same change then it is covariance. For example, the 2D vector (1,1) with the axes marked up in meters becomes (100,100) when you reduce the scale to centimeters - because what was 1m long is now 100cm long. Notice you scale the axis by 1/100 i.e meters to centimeters and the vector co-ordinates change by a factor of 100. Thus standard vectors are contravariant with respect to changes in the basis. The more complicated case is for a dual vector or functional, things work in the opposite way because a dual vector is a function. If x is a vector and y is a dual vector then xy or x.y, <x,y>, <x|y> or (x,y), the notation varies a lot, is a numeric value. To get the numeric value you simply multiple each co-ordinate of the vector by the corresponding coordinate of the dual and sum. That is if the vector is (a,b) and the dual is (c,d) then s=(a,b).(c,d)=ac+bd This is usually called the scalar or inner product. In other words a dual vector is a linear function that maps a standard vector to a number. Now consider the effect of changing the scale of the axes used for the dual vector. If you multiply its scale by 1/100 then as before the dual that was (c,d) becomes (100c,100d) but the dual vector that gives you the same result as (c,d) before the transformation, when applied to a vector is (c/100,d/100). For example is you have (a,b)(c,d)=ac+bd before the transformation then after the transformation you have (a,b)(100c,100d)=100(ac+bd) and hence the dual vector that produces the same result is (c/100,d/100). As the dual is a function it changed covariantly by a change in the basis. It is a wonderful result that if you change the basis of the vectors and the dual vectors in the same way e.g. by the same scaling then as one of them is contravariant and the covariant the scalar product is invariant. But to return to programming. <ASIN:1871962439> <ASIN:1871962587> |
||||
| Last Updated ( Friday, 20 November 2020 ) |
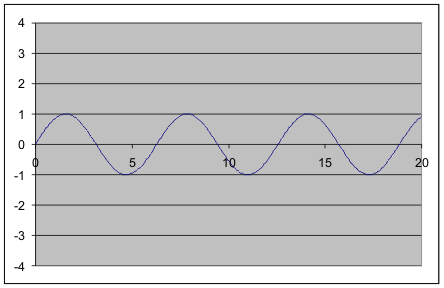 A graph of sin(x)
A graph of sin(x)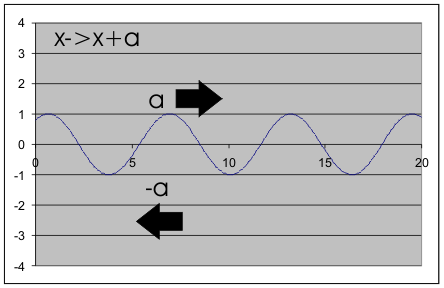 Changing x to x+a moves the graph in the -a direction
Changing x to x+a moves the graph in the -a direction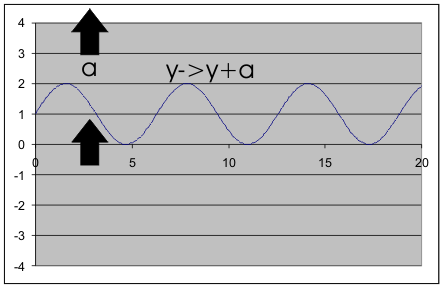 Changing y to y+a moves the graph up a units
Changing y to y+a moves the graph up a units