| Demystifying Pivot Tables |
| Written by Janet Swift | ||||||
| Friday, 20 August 2010 | ||||||
Page 2 of 2
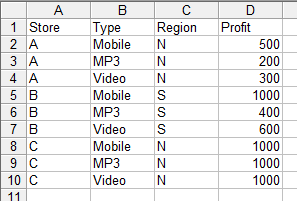
PivotGridThe control that we are going to use to demonstrate how Pivot Tables can be implemented in code is the Infragistics PivotGrid. This is part of the Infragistics new NetAdvantage Data Visualization toolsets, one for WPF, the other for Silverlight It is assumed that you have the Infragistics Data Visualization components installed and a copy of Visual Studio all setup and ready to go. You can, of course, try out the project using a free trial download of the NetAdvantage for WPF Data Visualization components. In most cases the PivotGrid would work with a pre-constructed data cube taken from say SQL server - a so called OLAP cube. In this case everything is pre-defined and you simply read the cube in and start working with it. In this sense it is actually simpler. However, going through the details of how to extract an OLAP cube from a SQL database is another story.... As the control can work with flat data from a variety of sources including an Excel spreadsheet for reasons of simplicity and practicality let' work with the simple profit spreadsheet that we have been developing as part of the explanation of what a pivot table is. The Excel spreadsheet Book1 contains the data in Sheet1 shown below:
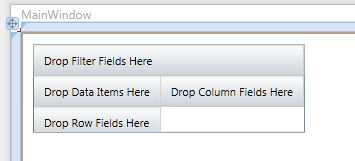
You can find this spreadsheet as part of the download of this project. We will also assume that the spreadsheet is stored in the C# project directory in the Debug sub-directory so that it can be read in more easily. Start a new C# project and drag and drop a XamPivotGrid control onto the page. As soon as the control has initialised you can see that it looks a bit like a vestigial 2D spreadsheet with placeholder in the row and column fields. The headings Drop Column Fields here and Drop Row Fields here are used to define the two categories that are used to create the 2D cross tabulation.
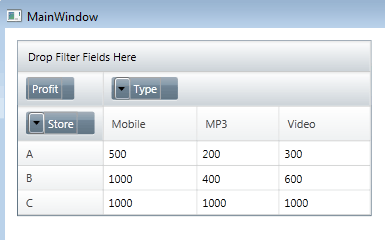
Although everything can be done using XAML and although it is more usual to allow the user to setup the PivotGrid using the associated PivotDataControl we will set up everything from code. Once you know how the code relates to the objects and properties involved using the PivotDataControl and converting to XAML is simpler. Our first task is to read in the Excel spreadsheet. You don't have to worry about having Excel installed on the client system as there is an Excel connector that understands the file format. So at this point make sure that the spreadsheet that you are going to work with has been saved in the project's Debug directory - if not change the file names and paths appropriately. To created the pivot table we first have to use a DataSource object to provide the data cube to the PivotGrid. In this case the DataSource has to take the Excel data, convert it into a flat data table add then convert this into a data cube. First we need to create a stream to read the Excel spreadsheet: Stream stream = new FileStream( Specifying FileShare.ReadWrite allows you to keep the spreadsheet open in Excel while the program is running. Next we need to create and use a FlatDataSource object. The first thing to do is specify the connection to the Excel spreadsheet - which stream to read and the name of the sheet: FlatDataSource flatDataSource = At this point we have the FlatDataSource set up so that it knows where to get the data from to make up the cube. We haven't supplied the information to tell it what constitutes the data that is to be used to cross tabulate and the data that is the value to be cross tabulated. All of the data is identified by the column headings i.e. the text in the Row 0 that makes up the heading for each column. Notice that the heading has to be in row zero. The column that contains the data to be cross tabulated is specified by the Measures property i.e. it is what you have measured. The two columns used to cross tabulate are specified by the Rows and Columns properties and for the moment we will simply treat these as the rows and columns of a 2D crosstab: flatDataSource.Measures = You can see that we have defined the measure to be the Profit column and the rows and columns of the crosstab correspond to the Store and Type column. Next we specify how the cube is to be constructed and some minor formatting niceties: flatDataSource.Cube = Everything about the data is now set up and a cube can be generated and used we simply need to remember to close the stream: xamPivotGrid1.DataSource=flatDataSource; If you now run the program you will discover it doesn't work because we need a set of using statements: using System.IO; and you need to make sure to add references to: InfragisticsWPF4.Controls.Grids. Some of these assemblies are added automatically when you drop the control on the form but the ones relating to Excel and the FlatData object aren't. If you now run the program you will see a very simple 2D crosstab:
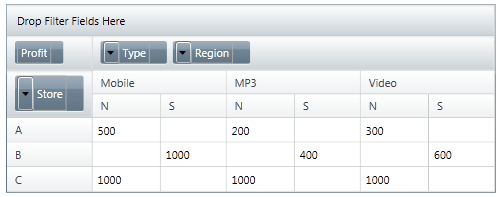
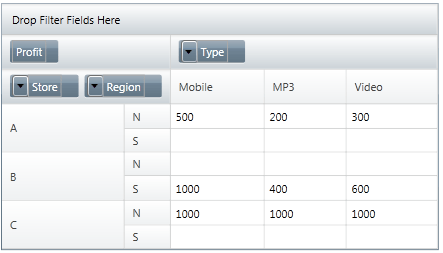
You should be able to follow how the data maps from the spreadsheet to the crosstab. There are many more properties that you can tweet to specify the mapping more accurately - formatting for instance - but this is the simplest relationship you can work with. You can also see that the buttons in the top left-hand corner invite user interaction. If you try them you will discover that the program crashes - you haven't set everything up for this just yet. Before moving on to consider interaction lets make the grid more than two-dimensional by adding the Region category. If you change the Columns specification to: flatDataSource.Columns = this says that the columns are classified on Type and and sub-category Region. The result is a tree style pivot table:
If you change the Rows property instead to read: flatDataSource.Rows = the result is the same but now the sub-category is listed as part of the row structure:
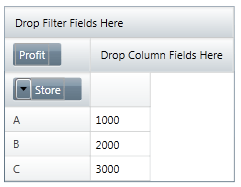
The idea is that you can specify a list of categories to be used to create either the rows or the columns using an obvious notation: [cat1],[cat2],[cat3] and so on... If you specify more than one set of categories between square brackets e.g. [cat1,cat2] then the data is aggregated on those categories. For example: flatDataSource.Columns = leaves only the Store category to cross tabulate:
This is a good start but there is so much more that we can do. In particular we can let the user select the categories and how they are displayed, we can add aggregating functions and more. To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Twitter, Facebook or Linkedin. 
<ASIN:0321508793> <ASIN:0470591617> <ASIN:1590594320> <ASIN:1119518164> <ASIN:0789743132> <ASIN:1590599209> |
||||||
| Last Updated ( Monday, 15 July 2019 ) |