| QuickSort Exposed |
| Written by Mike James | |||||
| Thursday, 24 June 2021 | |||||
Page 2 of 4
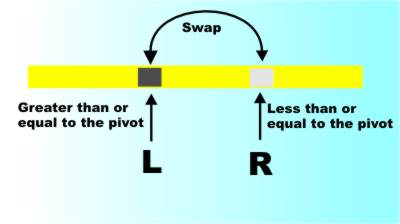
The Quicksort DivisionThe simplest way to describe how Quicksort works is by way of an example. Starting with a list of number that you want to sort 2 4 6 3 7 9 1 step one is to pick a value to act as a “pivot”. It is usual to pick one of the numbers that are actually in the list but this isn’t essential and it often leads to a misunderstanding of the overall method. However let’s stick with tradition and pick a roughly “middle” value, 3 say. 2 4 6 3 7 9 1 Step two uses the pivot value to divide the list into two parts. Values smaller than or equal to the pivot are moved to its left and values larger than the pivot are moved to its right. 2 1 3 7 9 6 4 Now you can see that the list is divided into two parts – values less than or equal to the pivot and values that are greater than the pivot – <= | > Notice that the pivot has moved its position in the array. How does this help? The list clearly isn’t fully sorted but you should be able to see that to put it into order there is no need to move any elements between the two parts. The values bigger than the pivot may have to be rearranged to put the list in order but they don’t have to be swapped with any element in the “less than or equal to” portion. They might not be in exactly the right place but they are in the right “half” of the list. As you only need to examine each value once and move it to its new location in theory the splitting should be possible to achieve in O(n) operations and so repeating the action until we reach a list with only one element – which is obviously in order – gives an algorithm that works in O(n log2 n) which is a lot better than O(n2) of most sorting algorithms. Notice that there is no need for the pivot to be a value in the list of numbers the method still works. It still divides the list into values less than or equal to the pivot and greater than the pivot. Of course for the method to be efficient the pivot should divide the list into two equal halves – and this means it is a good idea to choose a value that is in the list. So to summarize: We have a "divide and conquer" algorithm for sorting. All we have to do is pick a value and divide the list into a portion less than or equal to the value and a portion bigger than the value and we have decoupled the two portions as far as sorting goes. The values are not in their correct locations but they are in the correct portion. The list can be sorted by treating the two portions independently and this is the only requirement of the "division" part of the algorithm. Practical in-place QSThat’s it. That’s all there is to the QS method – but in this form it isn’t very practical. The biggest problem is that we haven’t given an exact algorithm for doing the division and if possible this should be an “in-place” algorithm which sorts the values using nothing but the array that they are supplied in. An “in-place” algorithm suggests that we need to use something that swaps values that need to be moved to opposite ends of the array. There is a sense in which this "swap" algorithm is an additional idea to the divide and conquer principle that gives us our basic quick sort as described so far. Consider the following swap algorithm:
So the algorithm goes: scan from both ends until you find something that is in the wrong place and then swap them over. This simple description hides a lot of detail. The main problem is when does the scan stop and where is the division point for the array, i.e. where is the location that divides the list into values less than or equal to the pivot and values larger than the pivot?
The answer to these questions depends on whether or not the pivot is an actual value in the array. It is usual to pick a pivot value that is in the array and this leads to the classical version of the algorithm that uses the pivot as a “sentinel” which stops both scans falling off the end of the array. How? Simple just make sure that neither the left or the right pointer can pass the pivot value. So the algorithm for the left pointer L is
And for the right pointer it is
As long as pivot is in the list of values we can be sure that both loops end because in this case for some L, A(L)=pivot and for some R A(R)=pivot and hence both loops come to rest on the pivot.
The scan and swap So both loops scan along until they find a value in the wrong place and then they swap the values over. Two questions - what happens when one of the scans hits the pivot and how do the scans end? The important thing is that for the pivot to be handled correctly the scan pointers must not be updated before the loops are started again. That is if you try
Then the update will be correct for all values that are swapped except when one of them is the pivot. Why?
<ASIN:0201350882> <ASIN:0201657880> <ASIN:0321637135> <ASIN:0521614104> |
|||||
| Last Updated ( Thursday, 24 June 2021 ) |