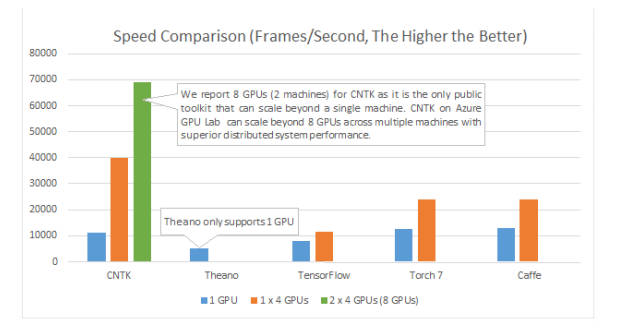
There are many different ways to implement a neural network including writing custom code in the language of your choice. TensorFlow is an attractive proposition but should you commit to using a tool supplied by Google even if it is open source? A new paper compares Caffe, CNTK, Theano, Torcha and TensorFlow.
Google's Machine Learning framework TensorFlow was open-sourced in November 2015 and has since built a growing community around it. TensorFlow is supposed to be flexible for research purposes while also allowing its models to be deployed productively. This work is aimed towards people with experience in Machine Learning considering whether they should use TensorFlow in their environment. Several aspects of the framework important for such a decision are examined, such as the heterogenity, extensibility and its computation graph. A pure Python implementation of linear classification is compared with an implementation utilizing TensorFlow. I also contrast TensorFlow to other popular frameworks with respect to modeling capability, deployment and performance and give a brief description of the current adaption of the framework.
So what is the answer? The Conclusion begins with:
"So should you use TensorFlow? It depends."
and goes on to say:
"TensorFlow is worth taking a look at if you currently write your networks in pure Python and want to express your model with less overhead. It could be the right choice if you do not focus on cutting-edge performance but rather on straight-forward implementations of concepts and want a framework backed by a strong player and a big emerging community."
Yes it is amazing what people think of to get neural networks to do. In this case the researchers used a recursive neural network to estimate the price of a house - thus putting real estate agents out of a job, as far as price estimation is concerned at least.
"Real estate appraisal, which is the process of estimating the price for real estate properties, is crucial for both buyers and sellers as the basis for negotiation and transaction. Traditionally, the repeat sales model has been widely adopted to estimate real estate price. However, it depends the design and calculation of a complex economic related index, which is challenging to estimate accurately.
Today, real estate brokers provide easy access to detailed online information on real estate properties to their clients. We are interested in estimating the real estate price from these large amounts of easily accessed data. In particular, we analyze the prediction power of online house pictures, which is one of the key factors for online users to make a potential visiting decision. The development of robust computer vision algorithms makes the analysis of visual content possible.
In this work, we employ a Recurrent Neural Network (RNN) to predict real estate price using the state-of-the-art visual features. The experimental results indicate that our model outperforms several of other state-of-the-art baseline algorithms in terms of both mean absolute error (MAE) and mean absolute percentage error (MAPE)."
Google's Deepmind and Oxford University have produced a neural network that can outperform humans at lip reading:
"The goal of this work is to recognise phrases and sentences being spoken by a talking face, with or without the audio. Unlike previous works that have focussed on recognising a limited number of words or phrases, we tackle lip reading as an open-world problem - unconstrained natural language sentences, and in the wild videos. Our key contributions are:
(1) a 'Watch, Listen, Attend and Spell' (WLAS) network that learns to transcribe videos of mouth motion to characters;
(2) a curriculum learning strategy to accelerate training and to reduce overfitting;
(3) a 'Lip Reading Sentences' (LRS) dataset for visual speech recognition, consisting of over 100,000 natural sentences from British television.
The WLAS model trained on the LRS dataset surpasses the performance of all previous work on standard lip reading benchmark datasets, often by a significant margin. This lip reading performance beats a professional lip reader on videos from BBC television, and we also demonstrate that visual information helps to improve speech recognition performance even when the audio is available.
It is clear that this raises so many questions and possibilities that it is clearly a major break though. How long before we see commercial applications?
Fundación Biodiversa in Colombia has become the first pilot of Microsoft's Project SPARROW. SPARROW, developed by Microsoft's AI for Good Lab, is an AI-powered edge computing solution designed to mon [ ... ]
For its Octoverse event, GitHub recorded an interview with Guido van Rossum, the creator of Python. From it we learn about the origins of Python and its name and its role in the age of AI.