| GaussianFace Recognizes Faces Better Than Humans |
| Written by Mike James | |||
| Friday, 25 April 2014 | |||
|
For the first time a face recognition program outperforms humans at saying if two photos are of the same person. We are very well tuned to the task of face recognition and we are very good at it. Now we have a program that can beat humans at the face verification task - where you are shown two photos of and all you have to do is say if it is the same face or different. You might think that this is a much easier task than matching a given face to a large number of candidates, but you haven't seen the Labelled Faces in the Wild (LFW) set of test images. The wide range of poses, light conditions and poor photography makes it a tough problem. The AI system was designed at the Chinese of Hong Kong by Chaochao Lu and Xiaoou Tang to classify the LFW set but it also learned from a range of other photo datasets - a sample from which can be seen below.
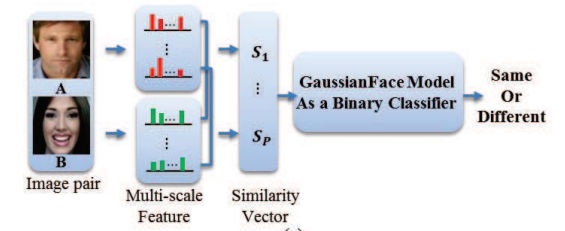
If you have been following recent developments in AI, you will probably be expecting that the approach used is yet another of the wonderful achievements of deep neural networks - but no. In this case the approach is a straightforward, but carefully worked out, piece of machine learning. The system was engineered in the sense that the researchers put components together to make a multi-step system. The first step is not really explained in the paper. After this each of the photos in the training and test set was normalized by a transformation that placed five facial landmarks - two eyes, nose and two mouth corners - at fixed positions within a 150x120 pixel image. The image is then divided into a set of overlapping 25x25 pixel patches and multi-scale Local Binary Pattern LBP features are extracted. The LBP features form the features that are feed into the machine learning system. The machine learning system is based on a modification of the classical Fisher Discriminant technique - the Kernel Fisher Discriminant Analysis or KFDA. The researchers also invent a more efficient form of the analysis - Discriminative Gaussian Process Latent Variable Model - which they have named for the sake of shortness GaussianFace.
Next they used a lot of data to train their classifier and feature extractor. The KFDA attempts to find composite features which best separate the data and then uses those features to classify the data. The data set used for training was very big - 20,000 matched images and 20,000 unmatched images. More importantly a range of different datasets were used to obtain a wider variation in distribution of features. The results show that the new method not only outperforms all of the existing methods of face verification, but also beats human performance (at 97.53%) by almost a full percent (98.52%). You need to remember that the task is to say if two photos are of the same person or not and the human performance is using photos cropped to show only the face. If you can see more of the body then human performance improves to 99.2%.
Errors made by GaussianFace - the top row are the same people and the bottom row shows two different people.
What is interesting about this result is that the method is based on classical discriminant analysis plus some clever extensions to make it non-linear and able to optimize its own performance. It is also clear that the total amount of data used is important, although notice that the other methods that GaussianFace was compared to failed to take as much advantage of the additional data. At the end of the paper the researchers note that the training was slow and that to extend the method to other tasks a better implementation, possibly GPU-based, is needed. Is there a practical use for this technology? Such high accuracy face verification might be just what is needed for security applications where your face unlocks the system. However, there is a lot more work to be done.
More Informationhttp://arxiv.org/abs/1404.3840 Related ArticlesGoogle's Deep Learning AI Knows Where You Live And Can Crack CAPTCHA Google Uses AI to Find Where You Live Yann LeCun Recruited For Facebook's New AI Group Deep Learning Researchers To Work For Google Google Explains How AI Photo Search Works Deep Learning Powers BING Voice Input Google Has Another Machine Vision Breakthrough? Google's Deep Learning - Speech Recognition Never Ending Image Learner Sees, Understands, Learns
To be informed about new articles on I Programmer, install the I Programmer Toolbar, subscribe to the RSS feed, follow us on, Twitter, Facebook, Google+ or Linkedin, or sign up for our weekly newsletter.

Comments
or email your comment to: comments@i-programmer.info
|
|||
| Last Updated ( Saturday, 26 April 2014 ) |