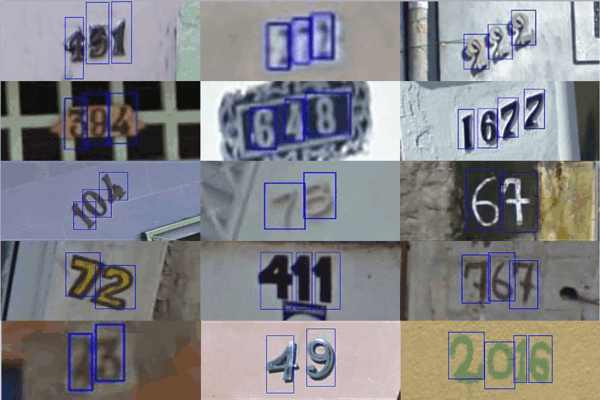| Google's Deep Learning AI Knows Where You Live And Can Crack CAPTCHA |
| Written by Harry Fairhead | |||
| Monday, 21 April 2014 | |||
|
A while back we reported on Google's attempts at creating machine vision that was good enough to read house numbers photographed in Street View. Performance has now got a whole lot better since the team switched to a deep convolutional neural network. After trying out the standard "engineering" approaches to machine vision Google seems to have found that convolutional neural networks are not only good at recognizing kittens in You Tube videos, but can do useful work. Google has a lot of pictures of house fronts complete with house numbers and the idea is that, if it is possible to read the house number, the photo can be geolocated all the more accurately. Back in 2011 a research team started work on building an OCR module that could work with the unstructured photos sent by Google StreetView car. The idea was that OCR is a fairly well solved problem in the sense that it can achieve accuracies as good as humans for scanned in documents. However, dealing with house number scattered in different places in photos is a much bigger problem. The team first tried to solve the problem by creating algorithms that localized the house number to a small area of the photo and then standard OCR algorithms could be used. Using hand crafted features they got up to 85% accuracy and with machine learning achieved 90% accuracy, which has to be compared to a human accuracy of 98%. Clearly this is good, but there is room to do at least 8% better.
House numbers where things went wrong - transcribed numbers v ground truth. The new approach throws away the "engineering" approach of putting together subsystems in favour of allowing a deep neural network to learn what has to be done to recognize and read the house numbers. Deep neural networks are systems of layers of artificial neurons that are trained by simply being "shown" the photographs. What is remarkable is that the system achieved an over 96% accuracy in recognizing complete house numbers and close to a 98% accuracy on single digits. This essentially solves the problem that started it all and from now on Street View "knows" the address of most of the houses it photographs. I leave others more paranoid than I am to work out any privacy or security implications of this. After cracking the house number problem, the team turned its neural network on the reCAPTCHA problem - where humans are challenged to read distorted characters to prove that they are indeed human. If you have tried the test you will find the reported 99.8% success rate on the hardest category of puzzles even more remarkable than the house number result. Most humans have difficulty with some of the easier puzzles. It seems now that the inability to do well at reCAPTCHA is proof that you are human, not the ability to read them.
CAPTCHAs that the network was able to read
Google claims that this isn't a problem for its reCAPTCHA bot filter because it no longer relies heavily on recognition of distorted images. What seems to happen is that the puzzle is augmented by some sort of behavioral analysis that identifies bots by the way they interact with the puzzle and not just whether they get the answer right. It is worth thinking about this result for a moment. After trying to design a system that specifically solves a particular problem, a much better performance was achieved by training a general purpose learning system, i.e. a deep neural network. Of course, what made this possible was the very large amount of training data and the computing power to implement the training. We have known about neural networks for many decades and they always seemed promising, but never delivered usable results. It seems that we had the right answer all along, but lacked the data and computing power to train networks that were complex enough. The network used to read street numbers turned in its best performance when it had 6 or more layers - so the deep part really is necessary. There seems to be no point in engineering systems from modules designed to solve specific problems. Now all you need to do is present the data to a deep neural network. The research paper concludes: "Perhaps our most interesting finding is that neural networks can learn to perform complicated tasks such as simultaneous localization and segmentation of ordered sequences of objects. This approach of using a single neural network as an entire end-to-end system could be applicable to other problems, such as general text transcription or speech recognition."
More InformationMulti-digit Number Recognition from Street View Imagery using Deep Convolutional Neural Networks Reading Digits in Natural Images with Unsupervised Feature Learning Related ArticlesGoogle Uses AI to Find Where You Live Yann LeCun Recruited For Facebook's New AI Group Deep Learning Researchers To Work For Google Google Explains How AI Photo Search Works Deep Learning Powers BING Voice Input Google Has Another Machine Vision Breakthrough? Google's Deep Learning - Speech Recognition Never Ending Image Learner Sees, Understands, Learns
To be informed about new articles on I Programmer, install the I Programmer Toolbar, subscribe to the RSS feed, follow us on, Twitter, Facebook, Google+ or Linkedin, or sign up for our weekly newsletter.

Comments
or email your comment to: comments@i-programmer.info
|
|||
| Last Updated ( Monday, 21 April 2014 ) |