| All About Kinect |
| Written by Harry Fairhead | ||||||
| Wednesday, 30 March 2011 | ||||||
Page 2 of 5
The softwareThe depth sensing hardware is the first feature that makes the Kinect special but without software it is just so much clever optics and processing. When Microsoft first released the Kinect it was very much Xbox and Microsoft applications only. It didn't take long for the USB connection to be decoded and open source USB drivers appeared on the web. With these you could connect the Kinect to a Linux or Windows machine and access the raw data. Only a few weeks later developing for Kinect became easier thanks to an open source initiative setup by PrimeSense the original designers of the Kinect hardware. All of the necessary APIs available as a project called OpenNI with drivers for Windows and Ubuntu. The only problem is that the drivers that they supply are for their own reference hardware. However changing the driver is a matter of modifying configuration files and this has been done for the Kinect and this is explained in the article Getting Started with PC Kinect
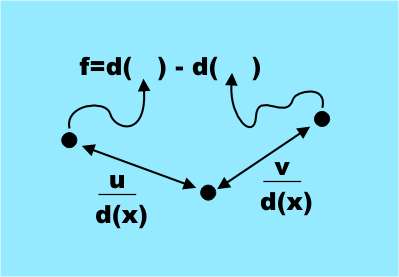
TrackingSo how does Kinect track people? There are two answers to this question. The old way and the new way designed by Microsoft Reasearch. The new Microsoft way of doing things has significant advantages but at the moment only Microsoft have access to it. It has been promised that an SDK for the Kinect will be made available in the future and this might includes some "middleware" that does body tracking - or it might not. Currently the only body tracking software that is available for general use is NITE from PrimeSense. This isn't open source but you can use it via a licence key that they provide at the OpenNI website. This works in the way that all body tracking software worked until Microsoft found a better way so lets look briefly at its principles of operation. The Nite software takes the raw depth map and finds a skeleton position that shows the body position of the subject. It does this by performing a segmentation of the depth map into objects and then tracks the objects as they move from frame-to-frame.. This is achieved by construct an avatar, i.e a model of the body that is being detected, and attempting to find a match in the data provided by the depth camera. Tracking is a matter of updating the match by moving the avatar as the data changes. This was the basis of the first Kinect software that Microsoft tried out and it didn't work well enough for a commercial product. After about a minute or so it tended to lose the track and then not be able to recover it. It also had the problem that it only worked for people whe were the same size and shape as the system's developer - because that was the size and shape of the avatar used for matching. Body recognitionMicrosoft Research has recently published a scientific paper and a video showing how the Kinect body tracking algorithm works - it's almost as amazing as some of the uses the Kinect has been put to! There are a number of different components that make Kinect a breakthrough. Its hardware is well designed and does the job at an affordable price. However once you have stopped being amazed by the fast depth measuring hardware your attention then has to fall on the way that it does body tracking. In this case the hero is a fairly classical pattern recognition technique but implemented with style. So what did Microsoft Research do about the problem to make the Kinect work so much better?They went back to first principles and decided to build a body recognition system that didn't depend on tracking but located body parts based on a local analysis of each pixel. Traditional pattern recognition works by training a decision making structure from lots of examples of the target. In order for this to work you generally present the classifier with lots of measurements of "features" which you hope contain the information needed to recognise the object. In many cases it is the task of designing the features to be measured that is the difficult task. The features that were used might surprise you in that they are simple and it is far from obvious that they do contain the information necessary to identify body parts. The features are all based on a simple formula: f=d(x+u/d(x))-d(x+v/d(x)) where (u,v) are a pair of displacement vectors and d(c) is the depth i.e. distance from the Kinect of the pixel at x. This is a very simple feature it is simply the difference in depth to two pixels offset from the target pixel by u and v.
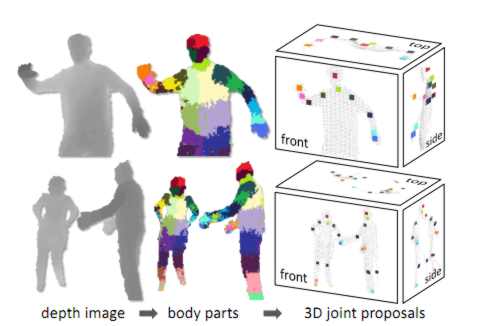
The only complication is that the offset is scaled by the distance of the target pixel i.e. divided by d(x). This makes the offset depth independent and scales them with the apparent size of the body. It is clear that these features measure something to do with the 3D shape of the area around the pixel - that they are sufficient to tell the difference between say an arm or a leg is another matter. What the team did next was to train a type of classifier called a decision forest, i.e. a collection of decision trees. Each tree was trained on a set of features on depth images that were pre-labeled with the target body parts. That is the decision trees were modified until they gave the correct classification for a particular body part across the test set of images. Training just three trees using 1 million test images took about a day using a 1000 core cluster. The trained classifiers assign a probably of a pixel being in each body part and the next stage of the algorithm simply picks out areas of maximum probability for each body part type. So an area will be assigned to the category "leg" if the leg classifier has a probability maximum in the area The final stage is to compute suggested joint positions relative to the areas identified as particular body parts. In the diagram below the different body part probability maxima are indicated as colored areas:
Notice that all of this is easy to calculate as it involves the depth values at three pixels and can be handled by the GPU. For this reason the system can run at 200 frames per second and it doesn't need an initial calibration pose. Because each frame is analysed independently and there is no tracking there is no problem with loss of the body image and it can handle multiple body images at the same time. Now that you know some of the detail of how it all works the following Microsoft Research video should make good sense: (You can also watch the video at: Microsoft Research) The Kinect is a remarkable achievement and it is all based on fairly standard classical pattern recognition but well applied. You also have to take into account the way that the availability of large multicore computational power allows the training set to be very large. One of the properties of pattern recognition techniques is that they might take ages to train but once trained the actually classification can be performed very quickly. Perhaps we are entering a new golden age when at last the computer power needed to make pattern recognition and machine learning work well enough to be practical. |
||||||
| Last Updated ( Thursday, 14 July 2011 ) |