| Assemblers and Assembly Language |
| Written by Harry Fairhead | ||||
| Friday, 03 May 2019 | ||||
Page 2 of 3
Abstraction Explosion!After you take the step of moving even a little bit away from machine code there seemed to be nothing stopping the mad headlong rush away from it as fast as possible. In the early days the technology needed to implement an assembler was very simple. All you needed was a lookup table of symbols. When the program contained the line:
the assembler simply split off the first three characters “MOV” and looked it up in a table that gave the machine code for it. Then it read the rest of the line and completed the instruction. The main difficulty in implementing an assembler is in the “read the rest of the line and complete the instruction” which is more difficult than you might think. For example, machine code only uses binary but a good assembler is going to let the programmer write numbers in hex or even better in decimal. So the assembler has to recognize the base used for a number, e.g. anything ending in H is in hex, and it has to convert the number to binary. As you can see, assemblers start to get complicated very quickly but this doesn’t matter because as computers became more sophisticated assemblers became increasingly essential and increasingly easy to create. The rush away from machine code is a natural one because you can start to create language facilities that just don’t exist in machine code or in the simple mnemonic codes used to represent it. As soon as you start to automate the conversion of mnemonic codes into machine code you start to think of ways that you can add instructions and features that make the programmer's life easier.
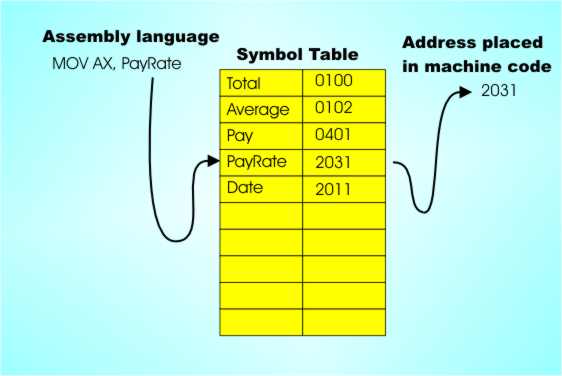
All you need is a lookup table to convert symbols to binary and you almost have an assembler. Symbols and addressesPerhaps the most important single invention of the assembler era was the symbolic address. The main part of an assembler was a symbol lookup table that came pre-loaded with all of the mnemonics and their corresponding machine code equivalents. Given you have a symbol table why not make more use of it? Machine code programmers have no choice but to write absolute addresses in their programs. For example:
means load the In most cases the programmer doesn’t actually care that memory location 0001H is used. The actual address is generally irrelevant as long as it is used consistently. That is, if you stored the pay rate in memory location 0001H then the next time you make use of the pay rate it should be fetched from memory location 0001H, but if you had used memory location 0002H instead of 0001H then that would be fine also – as long as you always used memory location 0002H when you wanted to use the pay rate. For most tasks the exact memory location that you use to store some data is irrelevant - as long as it is always used consistently. In the early days programmers would have to start their programs by performing manual memory allocation. that is they first assigned uses to particular memory locations - 001 will be the total, 002 the running count, 003 a temporary result and so on. Then as they programmed the action of the program they used the addresses that had been assigned in instructions Clearly trying to remember where you stored everything isn’t fun and it’s very error prone. The assembler idea, and its symbol table, can help again. Instead of using absolute memory addresses why not use symbolic addresses? That is use symbols in your programs that the assembler replaces with consistent addresses that it assigns. For example, you might write something like:
Here the first line isn’t a program instruction – it is an assembler declaration. It says that the symbol “PayRate” is to be considered to be a particular byte in memory, i.e. DB = Declare Byte. When the programmer writes in the next line MOV AL,PayRate it means replace PayRate with the actual address that it was allocated. Notice now that the assembler has taken on a new role in life – it is allocating memory! When the assembler translates the program to machine code it has to keep a table that tells it what address “PayRate” corresponds to and it has to allocate an address to “PayRate” when it meets its declaration for the first time. In fact this idea is too good to leave there and not only can the “DB” assembler directive tell it to allocate memory it also can tell it what to initialize that memory to - 10H in this example. So when the MOV AL,PayRate instruction is obeyed not only does this load To implement this use of symbolic addressing the assembler has to have a slightly more sophisticated symbol table and back in the early days many a computer science course would spend hours on hash tables and other techniques for fast lookup of symbols. Today lookup tables are a solved problem – unless you’re discussing millions and millions of symbols!
A slightly more sophisticated symbol table – one that can be added to – gives us variables |
||||
| Last Updated ( Saturday, 04 May 2019 ) |