| DeepMind's AlphaZero Triumphs At Chess |
| Written by Sue Gee | |||
| Thursday, 07 December 2017 | |||
|
DeepMind's latest program, AlphaZero, has used reinforcement learning from playing against itself to master the game of chess. Given the important role that chess has occupied in computer science, this is a big breakthrough for neural networks.
Back in March 2016, Mike James explained Why AlphaGo Changes Everything and now we can repeat the sentiment with respect to AlphaZero, the latest in the line of programs from the DeepMind.team. Information about AlphaZero comes in a paper that appeared this week authored by David Silver, Thomas Hubert, Julian Schrittwieser and other members of DeepMind including its founder and CEO Demis Hassabis. The most important detail is that AlphaZero is a fully generic algorithm which: replaces the handcrafted knowledge and domain-specific augmentations used in traditional game-playing programs with deep neural networks and a tabula rasa reinforcement learning algorithm. The AlphaZero algorithm was applied to chess, shogi (a Japanese version of chess played on a bigger board) and Go as as far as possible the same algorithm settings, network architecture, and hyper-parameters were used for all three games each of which used a separate instance of AlphaZero. Starting from random play, and given no domain knowledge except the game rules, AlphaZero convincingly defeated a world-champion program in each game, Stockfish for chess, Elmo for shogi and two versions of AlphaGo, within a period of 24 hours using self-play reinforcement learning.
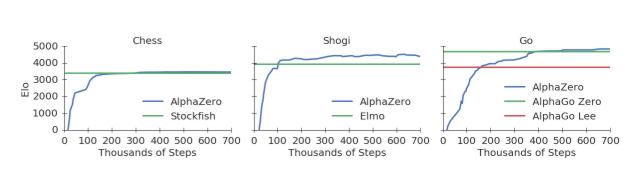
(click in charts to enlarge) The charts above show the Elo rating (i.e.relative skill level of players in competitor-versus-competitor games) achieved per number of steps. It reveals the typical learning curve for reinforcement learning of rapid improvement followed by a plateau. The paper clarifies: In chess, AlphaZero outperformed Stockfish after just 4 hours (300k steps); in shogi, AlphaZero outperformed Elmo after less than 2 hours (110k steps); and in Go, AlphaZero outperformed AlphaGo Lee after 8 hours (165k steps). In 50 games of chess playing White, AlphaZero won 25 games and drew the other 25; playing Black it chalked up 3 wins and 47 draws.
Are we happy about this? What about all that time invested in and alpha/beta pruning algorithms and heuristics for evaluation functions. We can now throw them out - and not only for chess. As this is a generic algorithm it can be put to other scenarios. As long as the compute power is available for the domain we are interested in just start with tabula rasa and let reinforcement learning take over. But yes, we are certainly happy. Artificial Intelligence has made amazing strides in just a few years and there is the promise of it being able to solve really difficult problems. It isn't yet everything we need and there are still things to work out and invent, but the ability of neural networks to capture hierarchical structure given only rewards to guide it goes well beyond what we might have expected only a short time ago. We don't yet have an AI brain, but we are assembling the components and seeing the basic tools emerging at long last.
More InformationMastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm Related ArticlesWhy AlphaGo Changes Everything AlphaGo Zero - From Nought To Top In 40 Days AlphGo Defeats World's Top Ranking Go Player AlphaGo To Play World Number One Go Player World Champion Go Player Challenges AlphaGo AlphaGo Revealed As Mystery Player On Winning Streak DeepMind's Differentiable Neural Network Thinks Deeply
To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Twitter, Facebook or Linkedin. 
Comments
or email your comment to: comments@i-programmer.info |
|||
| Last Updated ( Monday, 11 December 2017 ) |