| Picture - A Probabilistic Language |
| Written by Mike James | |||
| Wednesday, 15 April 2015 | |||
|
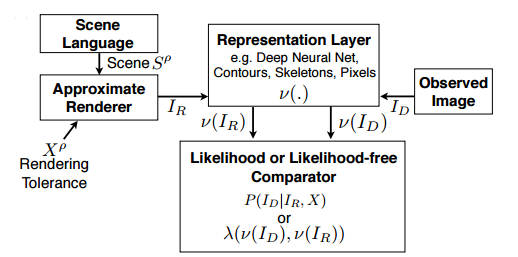
Computer vision is a booming research area at the moment and now we have a successful return to a method that was proposed very early on - analysis by synthesis. Researchers at MIT have created a language, Picture, based on Julia that makes it much easier to write programs that use probabilistic reasoning for 2D and even 3D based computer vision. Their work is to be presented at the Computer Vision and Pattern Recognition conference in June. The team's idea also makes use of analysis by synthesis, which is the general principle that to analyse something one approach is to find a mechanism that reproduces it. In the case of vision this is effectively inverse graphics. If you take a 3D model and render it then each of the pixels in the image has a determined color and brightness. Inverse graphics works the other way and attempts to find a 3D model that will produce the pixel intensities in a given image. By finding the right model you can understand what the system is looking at - a cube, tilted at 45 degrees, say. Inverse graphics sounds simple in theory, but in practice there are many 3D models that could have given rise to the pixel arrangement and so you need to use a statistical approach to find the best model. Picture is a probabilistic language that allows you to apply a standard template to a range of reverse graphics problems.
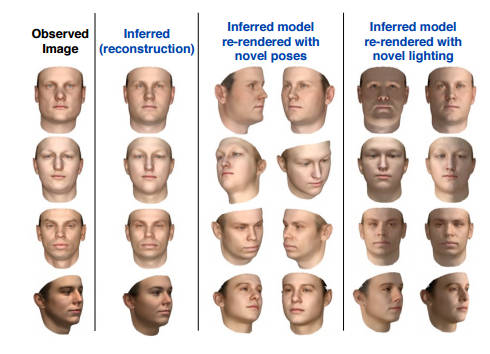
The scene language is used to describe the object you are looking for as a parametrized 3D model. For example a face is two eyes set symmetrically about a nose with parameters that give the size and separation of the eyes. The scene is then rendered and compared to the observed image. To make the comparison faster, a representation layer is used to convert both observed and generated image to a smaller set of features. These features can even be based on the output of a neural network applied to both images. An inference engine is where the learning happens. This uses some sort of adjustable representation of a probability distribution - either a Markov Chain Monte Carlo (MCMC) sampler or something more complicated like a Helmholtz machine. This is a very general approach and the language allows different applications to be put together in just a few lines of code. Of course, behind the scenes a lot of code is doing a lot of work. Three demonstration tasks were tackled. The first was constructing a 3D model of a face given only its 2D image. Once you have the 3D model you can generate views of the face from different positions, orientations and lighting conditions.
The second task was estimating 3D human pose. Given a set of photos work out how the body is positioned in 3D. The third task was to reconstruct a 3D CAD model of a solid from a 2D image. In all cases the system seems to work as well as the best alternative methods. What is interesting about this approach isn't really how successful it is. It is that we have a simple language that allows the expression of complex analysis by synthesis models. It is also that analysis by synthesis takes us well beyond the simple discrimination tasks that neural networks have been proved to be good at. When you have a model that can reproduce the 2D image you have an understanding of the scene that is much superior to just a classification into "dog" or "cat". The neural network is an example of an early approach to AI that didn't work originally due to the lack of powerful machines and so too is analysis by synthesis. Perhaps the two could be put to work together. It might even be the approach that eliminates the sensitivity of neural networks to small perturbations in the input that causes them to classify visually identical images as different things, as described in The Flaw Lurking In Every Deep Neural Net .
More InformationPicture: A Probabilistic Programming Language for Scene Perception Tejas D Kulkarni MIT, Pushmeet Kohli Microsoft Research,Joshua B Tenenbaum MIT and Vikash Mansinghka MIT. (pdf) Related ArticlesGoogle's DeepMind Learns To Play Arcade Games The Deep Flaw In All Neural Networks The Flaw Lurking In Every Deep Neural Net Neural Networks Describe What They See Neural Turing Machines Learn Their Algorithms Google's Deep Learning AI Knows Where You Live And Can Crack CAPTCHA Google Uses AI to Find Where You Live Deep Learning Researchers To Work For Google Google Explains How AI Photo Search Works Google Has Another Machine Vision Breakthrough?
To be informed about new articles on I Programmer, install the I Programmer Toolbar, subscribe to the RSS feed, follow us on, Twitter, Facebook, Google+ or Linkedin, or sign up for our weekly newsletter.

Comments
or email your comment to: comments@i-programmer.info |
|||
| Last Updated ( Thursday, 16 April 2015 ) |