This time around we have three great tips for the Linux shell addict, three sites that will increase your productivity and save valuable time in your daily interactions with the shell.
The first one is ok-b.org. It's a shell snippet search engine where you get to describe the task you are after in natural English and in return be presented with closely related snippets.
For example, in looking up "How to list only files?", will bring up:
Bash: How to list only files?
find . -maxdepth 1 -type f
ls -l | egrep -v '^d'
ls -l | grep -v '^d'
List only common parent directories for files
read -r FIRSTLINE DIR=$(dirname "$FIRSTLINE")
while read -r NEXTLINE; do until [[ "${NEXTLINE:0:${#DIR}}" = "$DIR" || "$DIR" = "/" ]]; do DIR=$(dirname "$DIR") done done
echo $DIR
How to list files in directory using bash?
for file in /source/directory/* do if [[ -f $file ]]; then #copy stuff .... fi done
Whereas in looking up "How to copy a directory recursively?", will bring up:
How to find files recursively by file type and copy them to a directory while in ssh?
Or, in "replace a piece of text in a number of files"
sed -i 's/old_link/new_link/g' file...
perl -p -i -e <regex> <folder>
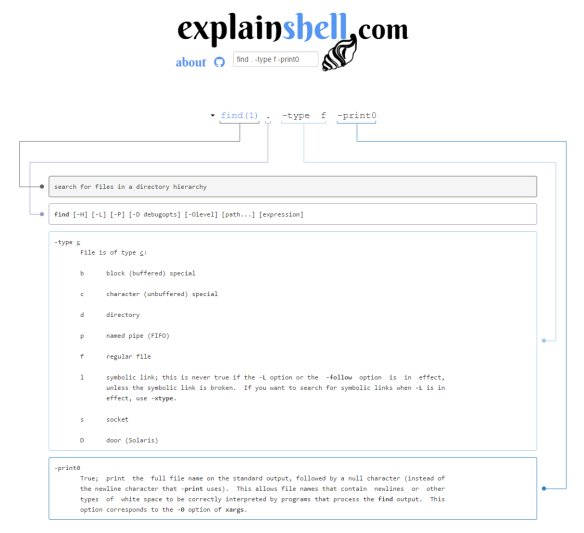
The second is explainshell.com. This search engine takes the exact opposite approach to ok-borg in that you get to type a shell command or sequence of commands and let explainshell parse them into their raw tokens and explain each one according to its man entry. Useful when finding snippets online but have no idea on what they do.
For example looking up :
"find . -type f -print0", returns:
"find . -type f -iname '*.cpp' -exec mv -t ./test/ {} \+" among others, has this to say on the \+ part , straight from find's man entry:
-exec command {} + This variant of the -exec action runs the specified command on the selected files, but the command line is built by appending each selected file name at the end; the total number of invocations of the command will be much less than the number of matched files. The command line is built in much the same way that xargs builds its command lines. Only one instance of `{}' is allowed within the command. The command is executed in the starting directory.
The last one is cmdchallenge.com.Its purpose is educational in that it assigns you challenges in order to sharpen your skills but can also act as a good host of snippets in a variety of tasks.
There's a limited number of challenges which require you to type the correct command in the interactive web based shell.
For example the challenge on
"# Print the current working directory"
requires typing pwd next to bash(0)>
If you get that right then it continues asking you to complete more 'difficult' challenges:
# You have a new challenge! # List names of all the files in the current # directory, one file per line. # bash(0)>
You can find all answers to all the challenges in the "See user submitted solutions for this challenge" area, which in this case will bring up a number of alternatives :
ls dir ls * ls . ls -c ls -b ls -k ls ./ ls -h ls -r echo * ls |more ls | cat echo | ls echo `ls` ls -p | grep -v / ls | awk '{print $1}' ls --format=single-column for A in * ;do echo $A;done find -type f | cut -d'/' -f2 ls -l | awk '{print $NF}' | tail -n +2
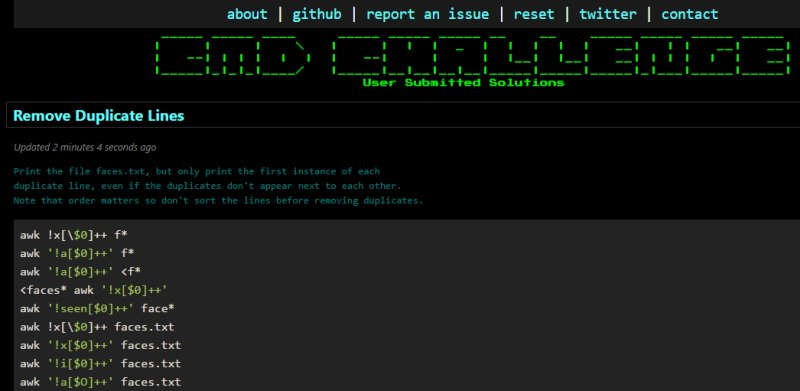
as already said, the number of challenges is not great, but nevertheless you can find a few advanced challenges too, for example :
"Print the file faces.txt, but only print the first instance of each duplicate line, even if the duplicates don't appear next to each other.Note that order matters so don't sort the lines before removing duplicates."
Apache Beam, the open source programming SDK for defining batch and streaming data-parallel processing pipelines, is now available in a new version. Apache Beam 2.70 has been released with improved su [ ... ]