| Unicode issues in Perl |
| Written by Nikos Vaggalis | ||||||
| Monday, 14 February 2011 | ||||||
Page 1 of 5 Unicode is supposed to make character handling easy, but living with a legacy system that uses multibyte encoding makes things complicated. This article looks at the real world of Perl Unicode integration and exposes a set of problems that also occurs in other languages and systems.
Windows stores filenames in Unicode, encoded in UTF16. Every Windows installation is fully Unicode capable but keeps compatibility with non-Unicode applications by using the “System Locale” as it was called under Windows 2000 or “Language for non-Unicode programs” as it is called in later Windows versions such as XP. The setting is found in the Advanced tab of the Regional and Language Options dialog in the Control Panel.
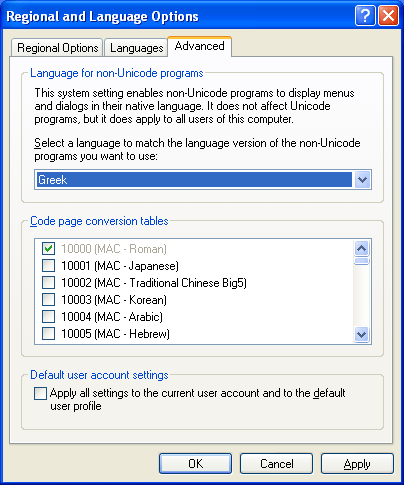
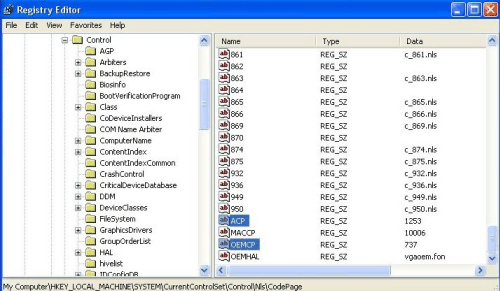
The choice made in this panel is very important as it has an installation wide effect and sets two registry keys:
(Click to expand) ACP stands for ANSI Code Page (extended ASCII) and OEMCP for OEM Code Page. Choosing Greek from the panel sets the system wide ANSI code page to 1253 and OEM to 737. The ACP code page is used to convert between Unicode and ANSI when needed and this effectively means that when a filename is fed into a non-Unicode application, our Perl script for example, the filename gets converted to ANSI by going through the following process:
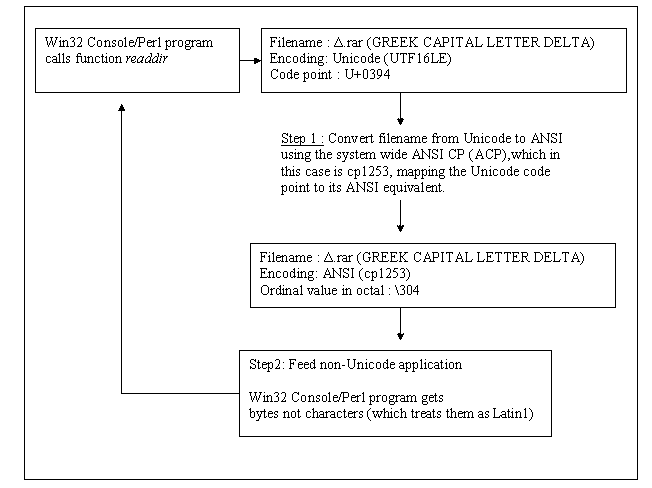
(Click on the flow chart to open it.) The points to note are that every character has a unique code point with a corresponding mapping to ANSI. Here the mapping was successful because the ANSI CP used was the correct one. Our Perl program gets plain bytes and does not know their actual encoding thus treats them as Latin1 ANSI by default. Also note that which system code page is going to be used, ACP or OEMCP, depends on what the caller function is looking at. This isn't Perl related; for example the C++ function RARProcessFile part of unrar.dll (UnRAR.dll is a 32-bit Windows dynamic-link library which provides file extraction from RAR archives) accepts two parameters DestPath and DestName and "both must be in OEM encoding. If necessary, use CharToOem to convert text to OEM before passing to this function." It needs the OEM encoding thus OEMCP is going to be used. In any case the outcome is equivalent thus we will use ANSI as the point of reference. Let’s examine a conversion that went wrong:
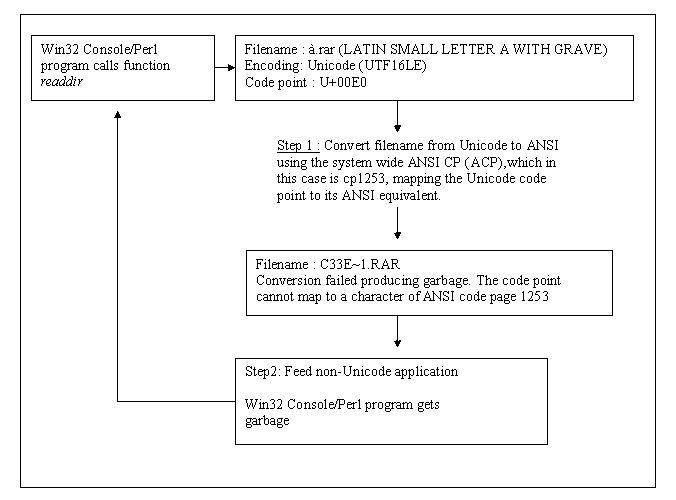
(Click on the flow chart to open it.)
We have a file named after an ANSI code page that does not match our system wide default code page; "à" or LATIN SMALL LETTER A WITH GRAVE belongs to cp1252/Latin1 not to cp1253, thus the mapping failed and the conversion produced garbage. Subsequently that garbage is fed into our program and any manipulation it engages in will be malformed. Essentially this means that if we have a non-Unicode application that is looking for Greek, it will function correctly with an OS that has its system default locale set to Greek, but a similar application designed for Russian say will break. This is not good. The same concept is also true for the Win32 API functions and they come in two versions, one for ANSI and one for Unicode. For example, the function SHBrowseForFolder comes in two flavors : SHBrowseForFolderA and SHBrowseForFolderW. Furthermore Console and GUI applications are affected as well. For example, you will sometimes see '?' from within a VB6 GUI instead of characters. This is because although VB6 is Unicode enabled, VB6 controls use ANSI internally. The point is anything that works in ANSI will go through the conversion process On the contrary if we have a file named "f" the conversion will be successfully completed since "f"'s ordinal value lies in the range between 0 to 127 and thus exists in every ANSI code page. |
||||||
| Last Updated ( Monday, 04 April 2011 ) |