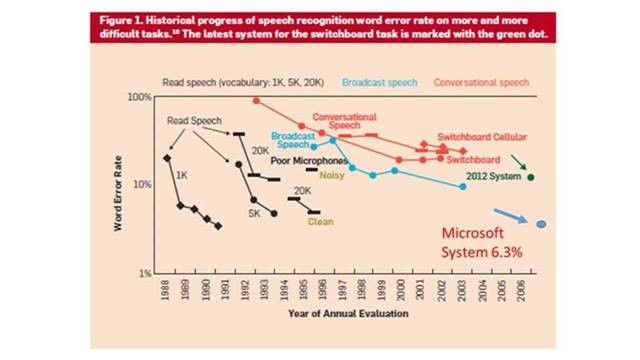
Xuedong Huang, the company’s chief speech scientist, reports that in a recent benchmark evaluation against the industry standard Switchboard speech recognition task, Microsoft researchers achieved a word error rate (WER) of 6.3 percent, the lowest in the industry.
In a research paper (see below), the scientists said:
“Our best single system achieves an error rate of 6.9% on the NIST 2000 Switchboard set. We believe this is the best performance reported to date for a recognition system not based on system combination. An ensemble of acoustic models advances the state of the art to 6.3% on the Switchboard test data.”
Geoffrey Zweig, principal researcher and manager of Microsoft’s Speech & Dialog research group, led the Switchboard speech recognition effort. He attributes the company’s industry-leading speech recognition results to the skills of its researchers, which led to the development of new training algorithms, highly optimized convolutional and recurrent neural net models, and the development of tools like CNTK.
We describe Microsoft's conversational speech recognition system, in which we combine recent developments in neural-network-based acoustic and language modeling to advance the state of the art on the Switchboard recognition task. Inspired by machine learning ensemble techniques, the system uses a range of convolutional and recurrent neural networks. I-vector modeling and lattice-free MMI training provide significant gains for all acoustic model architectures. Language model rescoring with multiple forward and backward running RNNLMs, and word posterior-based system combination provide a 20% boost. The best single system uses a ResNet architecture acoustic model with RNNLM rescoring, and achieves a word error rate of 6.9% on the NIST 2000 Switchboard task. The combined system has an error rate of 6.3%, representing an improvement over previously reported results on this benchmark task.
Machine learning (ML) models may be deemed confidential due to their sensitive training data, commercial value, or use in security applications. Increasingly often, confidential ML models are being deployed with publicly accessible query interfaces. ML-as-a-service ("predictive analytics") systems are an example: Some allow users to train models on potentially sensitive data and charge others for access on a pay-per-query basis.
The tension between model confidentiality and public access motivates our investigation of model extraction attacks. In such attacks, an adversary with black-box access, but no prior knowledge of an ML model's parameters or training data, aims to duplicate the functionality of (i.e., "steal") the model. Unlike in classical learning theory settings, ML-as-a-service offerings may accept partial feature vectors as inputs and include confidence values with predictions. Given these practices, we show simple, efficient attacks that extract target ML models with near-perfect fidelity for popular model classes including logistic regression, neural networks, and decision trees.
We demonstrate these attacks against the online services of BigML and Amazon Machine Learning. We further show that the natural countermeasure of omitting confidence values from model outputs still admits potentially harmful model extraction attacks. Our results highlight the need for careful ML model deployment and new model extraction countermeasures.
As an example, while both Inception V3 and Inception-ResNet-v2 models excel at identifying individual dog breeds, the new model does noticeably better. For instance, whereas the old model mistakenly reported Alaskan Malamute for the picture on the right, the new Inception-ResNet-v2 model correctly identifies the dog breeds in both images.
Shuttle has launched Neptune, a universal AI platform engineer that understands code, generates a deterministic infrastructure spec, provisions cloud resources, and integrates with AI coding tools and [ ... ]
Linux maintainers attending the Linux Kernel Maintainers Summit have said that Rust in the Linux kernel should no longer be treated as experimental, but rather as a core part of the kernel.