| How Do Open Source Deep Learning Frameworks Stack Up? |
| Written by Nikos Vaggalis | |||
| Wednesday, 24 April 2019 | |||
|
As the popularity of deep learning increases, finding application in all sorts of cases, so does the popularity of the various DL frameworks and libraries, making it difficult to choose between them. To provide an informed choice academic researchers devised and ran benchmarks. The results are published a a pre-print on arxiv.org with the title "A Detailed Comparative Study Of Open Source Deep Learning Frameworks". The purpose of this work by members of the Faculty of Computer and Information Technology at Jordan University of Science and Technology is to provide a qualitative and quantitative comparison among three of the most popular and most comprehensive DL frameworks, TensorFlow, Theano and CNTK, so that users can make an informed decision about the best DL framework that suits their needs. The reasoning behind the research is that although these frameworks use the same underlying algorithms, they implement them differently.They also provide extra features and facilities wrapped around these algorithms. The paper benchmarks each of the three frameworks on a number of datasets pertaining to the cases of image processing, computer vision, speech processing and natural language processing to recommend the best suited for each case. But before it goes into that, it first provides a bird's eye overview on the basics - What a Neural Network and Artificial Neurons are, The Perceptron, the Activation Function, Single Layer Networks vs Multi Layer Networks. It then moves on to the Deep Neural Networks (DNN) explaining that: A DNN is simply a NN with more than one hidden layer of nonlinear processing units which extract the features by passing input data from a layer to another until a desirable output is produced", and that Backpropagation is "one of the most used algorithms in DL is the Backpropagation algorithm, which is used to train the network by updating the weights of the connections between sequential hidden layers. This process is repeated many times until the output matches the desired output. After looking at the differences between two most widely used networks the Convolutional (CNN) and Recurrent (RNN), it moves on to yet another overview, this time of the frameworks under examination, CNTK, TensorFlow and Theano. Microsoft Cognitive Toolkit (CNTK) is an Open source DL framework developed by Microsoft Research, Theano is an open source Python library developed at MILA lab at University of Montreal, and TensorFlow is an open source framework developed by Google Brain Team. Additionally Keras, an open source DL library developed in Python, is run on top of the frameworks,. Then on to the Benchmark itself which runs on a laptop with Windows 10x64 an Intel Core i7-6700HQ CPU @ 2.60GHz (4 cores), 16 GB RAM and a NVIDIA GEFORCE GTX 960m graphics card (Laptop) with PCI Express 3.0 bus support, 4 GB GDDR5 memory and 640 CUDA cores. It measures:
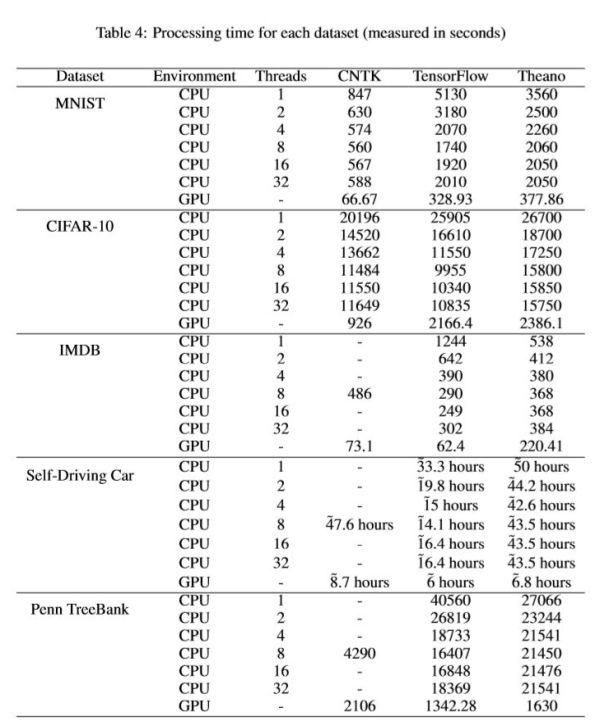
The benchmark uses the aforementioned frameworks to train a CNN and RNN on a number of datasets; the of MNIST, CIFAR-10, PennTreeBank, Self-Driving Cars and IMDB. The MNIST (Mixed National Institute of Standards and Technology) dataset is a computer vision database for handwritten digits. MNIST has a training set of 60,000 images and a testing set of 10,000 images. The CIFAR-10 dataset consists of 60,000 32×32 color images evenly distributed over ten classes: airplane, automobile, bird, cat, deer, dog, frog, horse, ship, and truck. There are 50,000 training images and 10,000 test images. PennTreeBank is a large annotated corpus of English comprising of the Brown and the Wall Street Journal Corpus. The IMDB dataset is an online dataset of information regarding films, TV programs and video games. It consists of 25,000 reviews labeled by the sentiment (positive/negative) of each review. The Self-Driving Car dataset uses a Udacity’s Self-Driving Car simulator as a testbed for training an autonomous car.
The results of the benchmark first of all show that using a GPU rather than a CPU has superior results in almost all experiments, even when the CPU uses multiple threads.Then for each dataset the results are aggregated leading to a conclusion on the best framework for the the job at hand.For example, in the MNIST and CIFAR-10 datasets TensorFlow had the lowest the GPU utilization, followed by Theano and CNTK. For CPU utilization, Theano had the lowest utilization followed by TensorFlow and CNTK. For Memory utilization while using CPU and GPU, the results were close to each other. The same goes for the rest of the datasets.The winners are visible on the benchmark table above, but for the summary and conclusions you'll have to check the paper yourself. Suffice it to say that, overall, CNTK by Microsoft wins. A great paper if you want an overview of the most widely used DL algorithms and the best framework for each one. Obtaining the hard facts leads to better resource utilization, faster research and saving lots of valuable time.
More InformationA Detailed Comparative Study Of Open Source Deep Learning Frameworks
Related ArticlesTCAV Explains How AI Reaches A Decision Neural Networks In JavaScript With Brain.js Deep Angel-The AI of Future Media Manipulation aijs.rocks - JavaScript Enabled AI
To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Facebook or Linkedin.

Comments
or email your comment to: comments@i-programmer.info |
|||
| Last Updated ( Wednesday, 24 April 2019 ) |