| Cooperative AI Beats Humans at Quake CTF |
| Written by Nikos Vaggalis | |||
| Monday, 17 June 2019 | |||
|
Who said that only humans can collaborate? AI not only managed to break this barrier too, but it also managed to beat humans at their very own game. Fun aside, Capture the Flag competitions are difficult to win even for humans. In a competition like this, each competing team comprising of two or more teammates occupies a basecamp identified by a distinct flag. The team has to protect its flag at all cost, but at the same time capture and hold the other teams' flags in order to win the competition. It's the exact same thing happening when a country gets conquered, the winner folding the home flag to replace it with its own symbol. In tech slang, that's the definition of 'owned'.
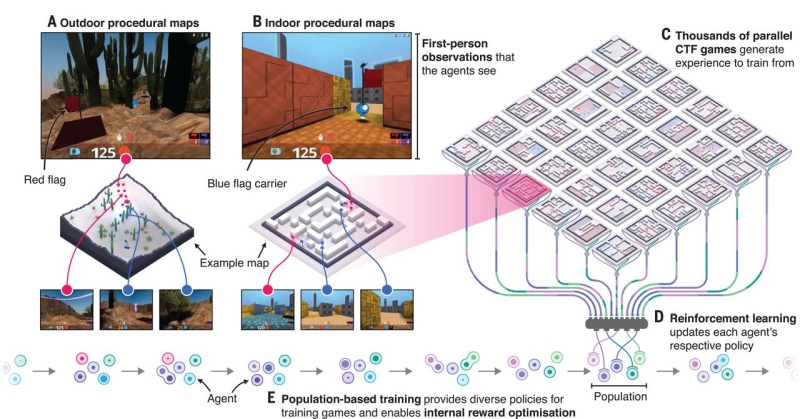
DeepMind managed to infiltrate this, until yesterday, exclusive club by training software agents to play Quake, employing its favorite method of Reinforcement Learning. Reinforcement Learning presumes no prior knowledge of the surroundings, nor previous experience. We've seen an example of that back in 2017 when we reported on Microsoft's The Malmo Challenge where the researchers were trying to make a Minecraft character climb a virtual hill. This might not have sounded such a big deal, but the difference was that this AI agent tried to overcome its hurdle through learning and interacting with its environment, not by being programmed to do so, but by trial and error. Project Malmo had organized a contest for any interested parties to develop agents who can, in the settings of a Minecraft game, work together to solve mini puzzles. Imagine a multiplayer Minecraft game, where the players are computer AI, not humans, looking to: "develop technology that can comprehend the intent of others, develop a shared problem-solving strategy and coordinate activity to efficiently accomplish a common task". Following in its footsteps, with a mix of RL and evolutionary/genetic algorithms, DeepMind's agents learn from experience generated by playing from within a population of teammates and opponents consuming just the first-person pixel view of the environment that each agent sees and the current game scores. RL provides the policy/rules for each agent while the genetic algorithm adapts the internal rewards and hyper-parameters to select the best performing agents by replacing their under-performing counterparts with mutated versions of better agents.
The genetic algorithm using simulated mutation and interbreeding evolves the population into newer populations that perform better than their ancestors. This evolutionary process runs continuously until a termination criterion is satisfied, hereby to find a policy that maximizes the expected cumulative reward, that is capture the flags in T time steps. If the run is successful, the result may be a solution (or approximate solution) to the problem. So just like under Malmo, it seems that we're well beyond the single AI agent phase and are entering a new age where AIs actively look to collaborate. The practical implications of such a development are far-reaching; for example in developing autonomous driving agents who can speak to each other in order to decide who's going to be given priority in crossing a road or to notify the other vehicles that stepping on the breaks is about to follow in order to avoid accidents. Ultimately this will lead to AI to Human collaboration, even in fields like that of war, as we've examined in Achieving Autonomous AI Is Closer Than We Think, where the touted ALPHA algorithm powers artificial wingmen that not only communicate with each other but also with their human operators, who under combat simulations even manage to outperform their human counterparts. By the way, if you've noticed the screenshot above, it's from Nvidia's RTX ray-traced remastering of Quake II, the three first levels of which are free of charge. To know more see Quake II RTX Available On Windows and Linux June 6th.
More InformationHuman-level performance in 3D multiplayer games with population-based reinforcement learning
Related ArticlesAchieving Autonomous AI Is Closer Than We Think
To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Twitter, Facebook or Linkedin.

Comments
or email your comment to: comments@i-programmer.info |
|||
| Last Updated ( Monday, 17 June 2019 ) |