| Computer Vision - Reconstruct -> Recognize |
| Written by Mike James | |||
| Saturday, 17 August 2019 | |||
|
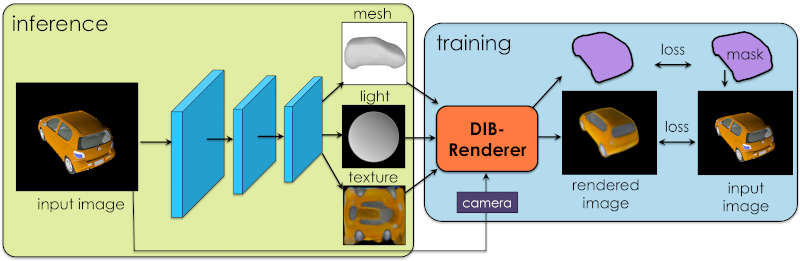
The idea of analysis by synthesis has been around for a long time, but it is only now being applied to computer vision. Could this be the missing component that makes AI able to see like we do? When you look at a scene you don't perceive flat 2D shapes but instead the 3D shapes that give rise to those 2D patterns of light, dark and color. Watch a strange blob of light change as a cube rotates and you don't see a strange blob changing in unpredictable ways, but a rotating cube. All of these observations suggest that the visual system is good at synthesizing the cause of the light fields that we see. This is the origin of the idea of analysis by synthesis. This suggests that you can only understand what you are looking at by having a model that generates it. Easy to say but hard to achieve. You can see the recent invention of capsule networks by Geoffrey Hinton et al. as an attempt to get neural networks to learn how to do the job. However, there might be a more direct route to the solution. It has been understood for some time that the key to generalized computer learning is the existence of a differentiable model. If you know how changing the parameters of the model changes its output then you can use this to learn. All you do is show the model what you want it to learn and adjust its parameters so that its output moves in the right direction, i.e. toward the desired output. This is what happens in back propagation. The neural network is differentiable and this is used to adjust its weights to move it towards the desired output - an action which is repeated over and over until the model is performing well enough. We know how to create models of the 3D world and how to project them into 2D. It is what happens in every graphics rendering pipeline. You start off with a 3D description of the world and the pipleline renders it in 2D on the screen so that you can process it and presumably reconstruct the 3D description in your head. So the idea is to use a rendering pipeline to learn how to infer 3D models from 2D scenes. The problem is that the rendering pipeline isn't necessarily differentiable. This is the problem that new research from a team consisting of people from NVIDIA, University of Toronto, McGill and Aalto have been working on: Many machine learning models operate on images, but ignore the fact that images are 2D projections formed by 3D geometry interacting with light, in a process called rendering. Enabling ML models to understand image formation might be key for generalization. However, due to an essential rasterization step involving discrete assignment operations, rendering pipelines are non-differentiable and thus largely inaccessible to gradient-based ML techniques. In this paper, we present DIB-R, a differentiable rendering framework which allows gradients to be analytically computed for all pixels in an image. The overall design of the system can be seen below:
There are lots of details of how the model was constructed to be differentiable and how the neural network was trained in the associated paper but how well does it work? The first column is the rendered image, the second column is predicted shape, third column is predicted texture, forth column is rendered car and last column is the predicted light. Notice that there are assumptions built into the model about what sort of rendering is being performed. So it does seem to work. There is so much more that needs to be explored. Once you have a differentiable renderer you can test many different approaches. Humans seem to have the ability to "understand" any 3D shape from just a 2D view, but they do occasionally get it wrong. It seems likely that when the same technique is applied to complex scenes with multiple objects some sort of hierarchy is going to have to be applied. That is, do you understand an image of a motor car as a single 3D model or do you break it down into components - wheels, boxes for the body and other parts and so on. This is the approach that a capsule network is supposed to take and it seems likely that this approach would benefit from it as well. Back in the early days of computer vision there were arguments about the engineering approach versus the neural network "end-to-end" approach. Typically, could you handcraft features that were easy to compute, understandable and effective? The answer seems to have been no, as neural networks are more successful deriving feature detectors that are not particularly easy to understand, but are very effective. Could it be that augmenting a neural network with an "engineering" approach provides a better solution. It is fairly clear the natural neural networks don't have 3D rendering pipelines but adding a differentiable renderer to an artificial neural network might provide the fastest way to understanding what is being seen.
The purple rectangle shows the input image. The first row shows the Ground Truth. The second row shows prediction with adversarial loss. And the third row shows prediction without adversarial loss. More InformationLearning to Predict 3D Objects with an Interpolation-based Differentiable Renderer Wenzheng Chen, Jun Gao, Huan Ling, Edward J. Smith, Jaakko Lehtinen, Alec Jacobson and Sanja Fidler Related ArticlesYou Only Look Once - Fast Object Detection Alien FaceHugger v Predator - Face Tracking Hots Up Google Releases Object Detector Nets For Mobile Google's Neural Networks See Even Better Google Has Another Machine Vision Breakthrough? To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Twitter, Facebook or Linkedin. 
Comments
or email your comment to: comments@i-programmer.info <ASIN:1848726945> |
|||
| Last Updated ( Saturday, 17 August 2019 ) |