| Google Adds SparkR Support On Cloud DataProc |
| Written by Kay Ewbank | |||
| Tuesday, 22 January 2019 | |||
|
Google is adding support for SparkR jobs on Cloud Dataproc, describing the move as the latest chapter in building R support on the Google Cloud Platform (GCP). SparkR is a package that provides a lightweight front end to use Apache Spark from R. The ability to run SparkR jobs means R developers can use dplyr-like operations on datasets of nearly any size stored in Cloud Storage. SparkR also supports distributed machine learning using MLlib.
Cloud Dataproc is GCP’s fully managed cloud service for running Apache Spark and Apache Hadoop clusters. The service has a Jobs API that can be used to submit SparkR jobs to a cluster without having to open firewalls to access web-based IDEs or SSH directly onto the master node. With the Jobs API, you can automate the repeatable R statistics you want to run on your datasets. The SparkR support can be accessed via the usual RStudio interface or using the SparkR Jobs API to execute SparkR code and automate tasks. If accessed from RStudio, the RStudio server can be running on either a Cloud Dataproc master node, a Google Compute Engine virtual machine or somewhere outside of GCP entirely. Users will only pay for the RStudio server while it is in use, and it can be shut it off when not in use. 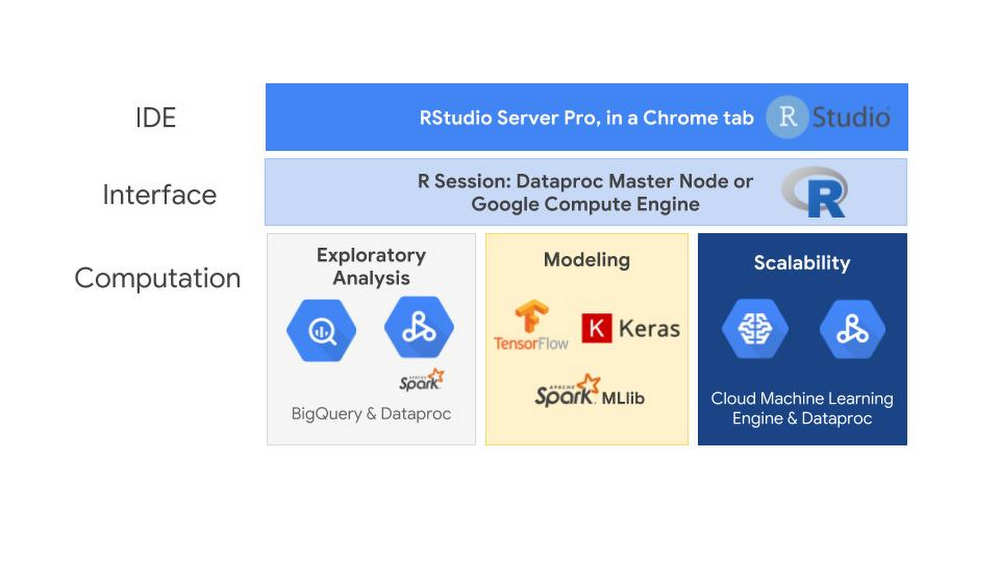 Alongside the support for SparkR, other R support options in GCP include the bigrquery package that can be used to work with data stored in BigQuery by allowing you to query BigQuery tables and retrieve metadata about your projects, datasets, tables, and jobs. There's also an R interface to TensorFlow that lets you work with the high-level Keras and Estimator APIs as well as the core TensorFlow API. SparkR jobs on Dataproc allow you to train and score Spark MLlib models at scale. There's also an R interface to Cloud Machine Learning (ML) Engine.
 More InformationRelated ArticlesApache Spark With Structured Streaming Visual Spark Studio IDE For Spark Apps Spark BI Gets Fine Grain Security Apache Spark Technical Preview
To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Twitter, Facebook or Linkedin. 
Comments
or email your comment to: comments@i-programmer.info |
|||
| Last Updated ( Tuesday, 22 January 2019 ) |
