| Kylin 2.3.0 Adds SQL Server Support |
| Written by Kay Ewbank | |||
| Tuesday, 13 March 2018 | |||
|
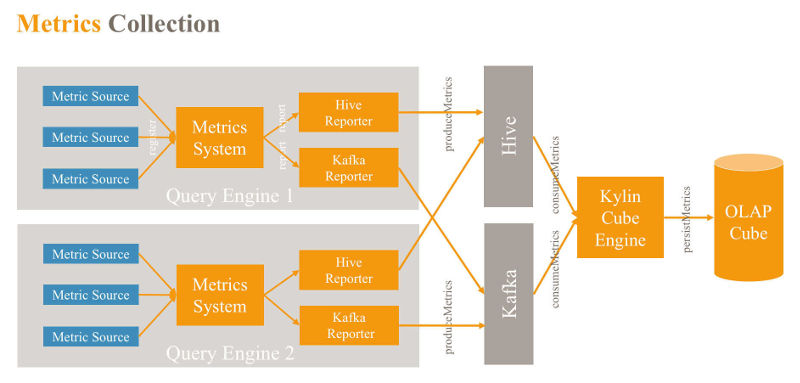
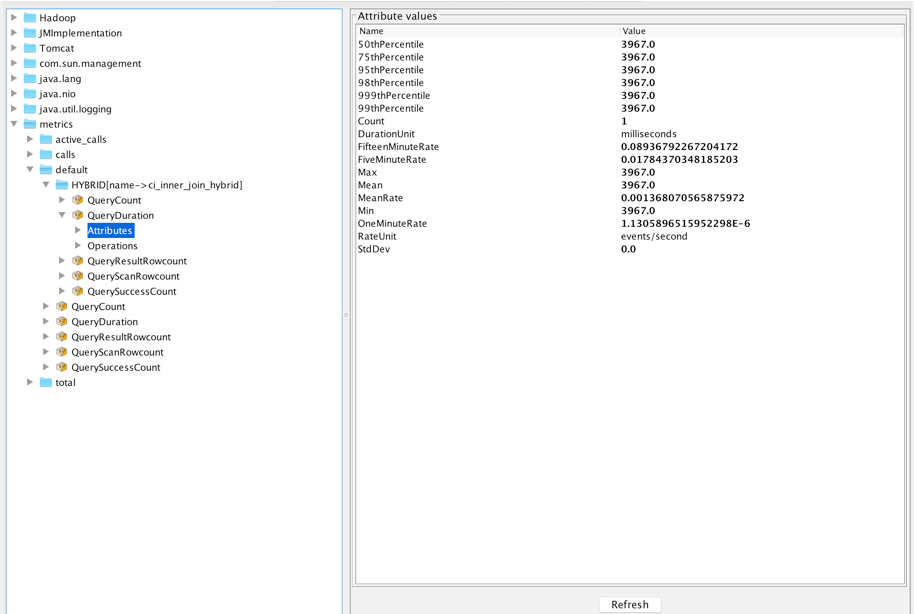
Apache Kylin has been updated with a new version that supports SparkSQL in building intermediate flat Hive tables. There's also a new Dropwizard-based metrics framework and a cube planner that can select the most cost-effective cuboids to build. Kylin is an open source distributed analytics engine designed to provide a SQL interface and multi-dimensional analysis (OLAP) on Apache. It was originally developed at eBay before becoming an Apache project. The Kylin OLAP Engine is made up of a metadata engine, a query engine, a job engine and a storage engine. It also includes a REST Server to service client requests. The query engine is based on Apache Calcite. The new version is a major release after 2.2, which was released last November.The first improvement to the new version is support for SparkSQL use when building intermediate flat Hive tables. SparkSQL is much faster then Hive when used to create flat tables. The second main improvement is the addition of a Dropwizard-based metrics framework. Dropwizard is a Java framework for developing high-performance, RESTful web services. The advantages of the new metric are that it is a well-defined metric model for frequently-needed metrics such as JVM metrics. It also has well-defined measurements for a wide range of metrics including max, mean, stddev, and mean_rate.
The metric also has built-in pluggable reporting frameworks including JMX, Console, Log, and JSON. A new tool called perflog has also been introduced. This traces call duration time and current active calls by recording them to the metric system. Another major main improvement to Kylin is the introduction of a dashboard that can be used to show Kylin service-related metrics such as query count, query latency, and job count. You can view dimensions including server level, project level, and cube level.
A cube planner has also been added to provide a way to choose which cuboids to build based on cost-based algorithms. OLAP solutions trade off online query speed against the cost of building offline cubes. To be resource efficient, It is critical to just pre-build the most valuable cuboids. Until now, decisions on partial cubes have had to be based on static rules, which runs the risk of complex rules and incorrect decisions because the user query patterns have changed. The new cube planner makes Apache Kylin more resource efficient. It intelligently builds a partial cube to minimize the cost of building a cube, then learns patterns from queries at runtime and dynamically recommends cuboids accordingly. The planner does not need static rules, and handles more dimensions than would be possible with static rules. You will also be able to adjust a non-cost-effective cuboid set to a cost-effective one based on historical queries. The addition of SQL Server (and RedShift) as data sources has been made possible because of changes to the plug-in architecture of version 2.0 of Kylin. Since then, you can have multiple data sources, cube engines and storage engines. The addition of SQL Server is likely to be followed by other standard RDBMS systems. Some tools such as Apache Sqoop can also be used to export data from RDBMS to HDFS, which can help Kylin get the data and then build that into cubes.
More InformationRelated ArticlesApache Kylin Gets Table Level ACL Management Apache Kylin Adds RDBMS Support Spark BI Gets Fine Grain Security
To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Facebook or Linkedin. 
Comments
or email your comment to: comments@i-programmer.info |
|||
| Last Updated ( Tuesday, 13 March 2018 ) |