| Cube.js Adds Storage Layer For Open Source Analytics |
| Written by Kay Ewbank |
| Wednesday, 23 June 2021 |
|
A custom pre-aggregation storage layer for Cube.js has been released, and the developers say this means Cube.js is now fully ready for use for operational analytics for any SQL-compliant database, data warehouse, or query engine. Cube.js is an open-source analytical API platform that you can use to add analytics to your applications. Used in its simplest way, it provides a better performance than that provided by the SQL-based data store. It achieves the performance through its in-memory cache and query queue. The new release, Cube Store, is more scalable and flexible so makes Cube.js better for operational analytics for SQL-compliant databases, data warehouses, and query engines.
Cube.js was designed to work with serverless data warehouses and query engines like Google BigQuery and AWS Athena. It uses multi-stage querying to tackle large data sets. The technology was originally created to provide the analysis for Statsbot, an enterprise business intelligence platform. Users of Statsbot asked if there was a way to use the query technology for their internal applications, and the developers pulled that technology out as Cube.js.
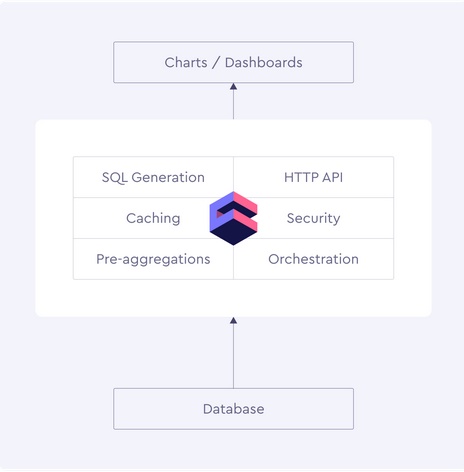
Cube.js works as the middleware, sitting between the database and the developer's frontend. The developer uses Cube.js as a service to handle the database connection, queuing of queries, caching and pre-aggregation. Pre-aggregations are materialized query results persisted as tables. In other words, they are condensed representations of source data that are pre-computed, partitioned, stored, and regularly refreshed so that select queries on them run very fast. Cube.js analyzes incoming queries against the set of pre-aggregation rules, and will find the most efficient choice to create a pre-aggregation table. Performing the query then becomes a multi-stage process. First, Cube.js checks if an up-to-date copy of the pre-aggregation exists. If it does, it will execute the query against the pre-aggregated tables instead of the raw data. What Cube Store adds is a "performant pre-aggregation storage layer for Cube.js". It's a distributed data store that can be used for pre-aggregation storage. Cube Store clusters each contain a single router node that handles incoming connections, manages database metadata, builds query plans, and orchestrates their execution. Alongside this, multiple worker nodes hold warmed up data and execute queries in parallel. The cluster also contains local or cloud-based blob storage holding pre-aggregated data in columnar format. For developers, the interesting part is that because it uses JavaScript, you can choose the best JavaScript front-end data visualization library for your purposes, connect to Cube.js, and it will handle all the backend details of access control, concurrency, and performance. More InformationRelated ArticlesGoogle Extends BigQuery For Multi-Cloud Analytics
|
| Last Updated ( Wednesday, 23 June 2021 ) |