| Apache Gravitino 0.9 Released |
| Written by Alex Denham | |||
| Thursday, 29 May 2025 | |||
|
Apache Gravitino v0.9.0-incubating has been released, with optimizations to the fileset catalogs and model catalogs, making it easier for users to manage their unstructured AI data and model data. Apache Gravitino is a high-performance, geo-distributed, and federated metadata lake. By using a technical data catalog and metadata lake, users can manage access and perform data governance for multiple data sources including filestores, relational databases, and event streams, while safely using multiple engines like Spark, Trino, or Flink on multiple formats on different cloud providers.
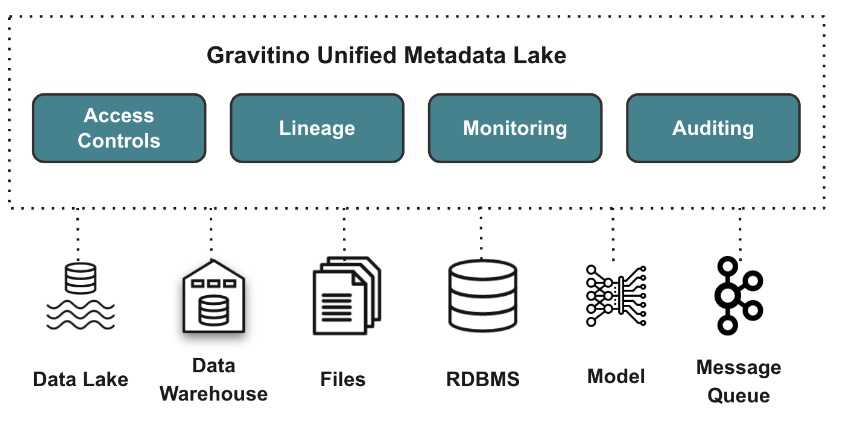
It provides users with unified metadata access for data and AI assets, and the developers describe it as the world's most powerful open data catalog for building a high-performance, geo-distributed and federated metadata lake. Gravitino provides several key features, starting with unified metadata management through a unified model and API to manage different types of metadata, including relational data such as Hive and MySQL; and and file-based metadata sources such as HDFS and S3.
It provides a governance layer for managing metadata with features like access control, auditing, and discovery; and connects directly to metadata sources via connectors, ensuring changes are instantly reflected between Gravitino and the underlying systems. Gravitino can be deployed across multiple regions or clouds, allowing instances to share metadata for a global cross-region view. It supports query engines enabling metadata access without modifying SQL dialects, and is expanding to manage both data and AI assets, with support for AI models and features currently in development. The improvements to the new release start with the model and fileset catalogs. Until now, the model catalog was immutable, so inflexible. Users can now alter models and model versions and add tags. Meanwhile, in the fileset catalog, Gravitino now supports multiple named storage locations within a single fileset and placeholder-based path generation. There's also new multiple location support, meaning users can reference data across different file systems such as HDFS, S3, and GCS through a unified fileset interface, each with a unique location name. The developers say the enhancements significantly improve the flexibility for multi-cloud environments and complex data organization patterns while maintaining a clean abstraction layer for data assets management. The Gravitino Virtual File System (GVFS) now supports accessing multiple locations within filesets, and has been refactored with a pluggable architecture allowing custom operations and hooks. Gravitino 0.9 is available now on GitHub.
More InformationRelated ArticlesApache Spark Now Understands English Spark 3 Improves Python and SQL Support DataBricks Open Sources All Of Delta Lake Databricks Delta Lake Now Open Source Apache Hive Adds Support For Set Operations To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Facebook or Linkedin. 
Comments
or email your comment to: comments@i-programmer.info |