| Flink Reaches Top Level Status |
| Written by Kay Ewbank | |||
| Thursday, 15 January 2015 | |||
|
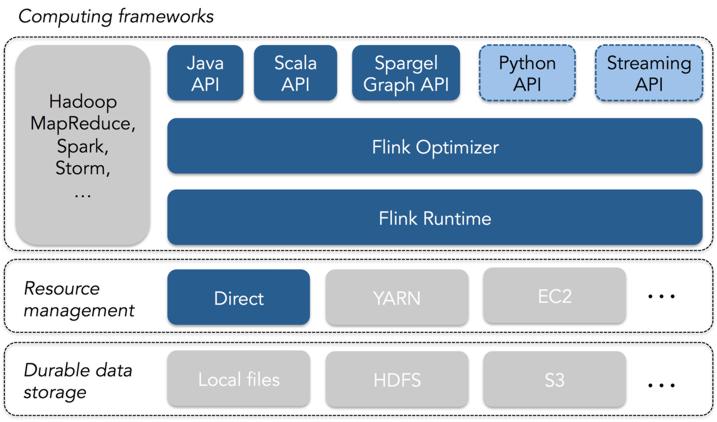
A data-processing language being developed by the Apache Software Foundation has been elevated to top-level status. Flink is open source, has APIs for Java and Scala and, with specialized APIs for graph processing, it is being proposed as an alternative to MapReduce. It also has its own runtime, and can be used to access Hadoop's distributed file system and YARN resource manager. It can be downloaded from its Apache incubator page.
Wriiting about the new language on the Data Artisans blog, developers working on the Flink project say that it provides a new approach to distributed data processing for the Hadoop ecosystem: “We believe that Flink embodies the next evolutionary step in distributed computation engines in the Hadoop eosystem. Flink is built on the principle, Write like a programming language, execute like a database.” The Data Artisans team says that while Flink is easy to use for programmers who are familiar with current popular tools in the Hadoop ecosystem, but introduces several innovative features that make its applications fast, robust, and easy to maintain.
Flink users write programs using one of its APIs. In addition to Java and Scala, the current release has Spargel , an API that implements a Pregel programing model. Other APIs, such as a Python API and a data streaming API, are under development. Flink’s APIs mostly follow the familiar model of bulk transformations on distributed object collections, popularized initially by MapReduce and extended by Apache Spark. What sets Flink apart from other available DAG processing systems is that it combines true streaming and batch processing applications in one system, and has a built-in mechanism for looping over data that makes machine learning and graph applications especially fast. The blog post says that “current engines for data processing are designed to perform their best in one of two cases: when the working set fits entirely in memory, or when the working set is too large to fit in memory.” It also argues that Flink’s runtime has great performance when the working set fits in memory, but is still be able to keep up with “memory pressure” from large datasets that do not fit in memory, or from other cluster applications that run concurrently and consume memory. The code you write is not actually the code that is executed. Instead, job execution in Flink is preceded by a cost-based optimization phase that generates the executable code. This phase chooses an execution plan for the program that is tailored the specific data sets (using statistics of the data) and cluster that the program will be executed on. This stage means an application can be used with underlying data changes and changes to cluster utilization without a need for rewriting or re-tuning to reflect these changes.
More InformationApache Flink: new kid on the block Related Articles
To be informed about new articles on I Programmer, install the I Programmer Toolbar, subscribe to the RSS feed, follow us on, Twitter, Facebook, Google+ or Linkedin, or sign up for our weekly newsletter.

Comments
or email your comment to: comments@i-programmer.info
|
|||
| Last Updated ( Thursday, 15 January 2015 ) |