| Hydra Turns PostgreSQL Into A Column Store |
| Written by Nikos Vaggalis | |||
| Monday, 13 November 2023 | |||
|
Hydra is an open-source extension that adds columnar tables to Postgres for efficient analytical reporting. Version 1.0 is generally available.
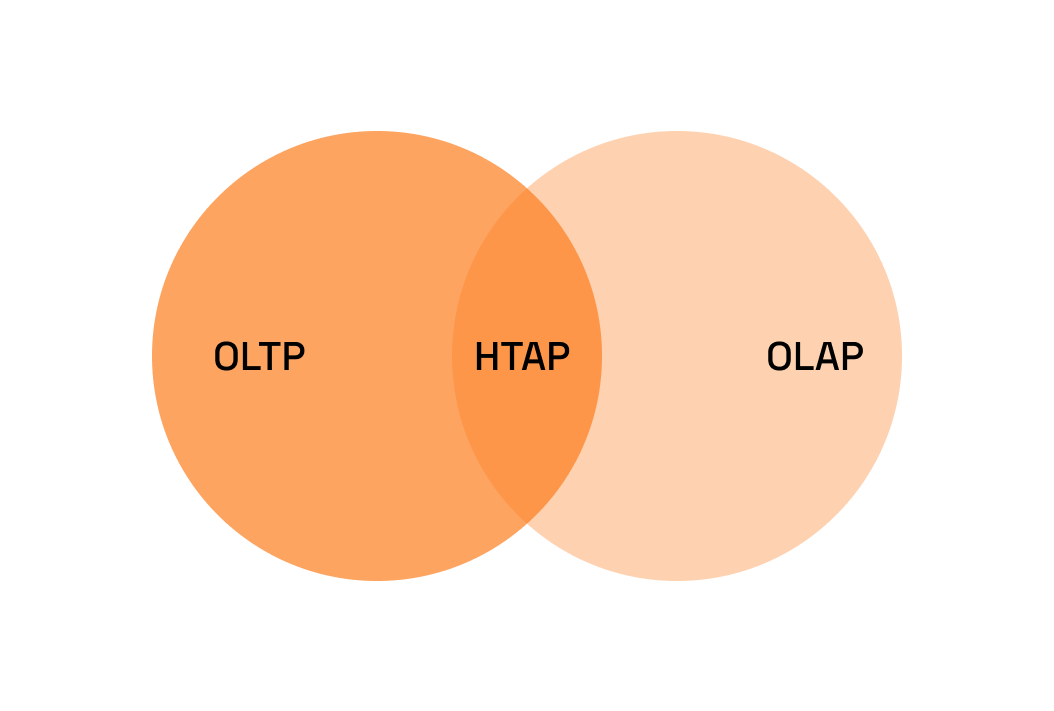
The age old question; OLAP or OLTP? Do you have a separate database for your transactional workloads and another for your warehousing needs? Hydra allows you to have both under the same roof. We have many times in the past discussed Postgre's extensibility capabilities. With the right plugins you can turn it into a Vector Store, a Message Queue and in this case a Column Store. As a refresher, a column-oriented database defines tables in column format rather than the usual row oriented format. This immediately gives those stores the edge over OLTP engines when doing analytics and data mining, where you typically want aggregation operations on the values of columns. As such That segregation was the world before the emergence of HTAP. HTAP is a hybrid architecture that combines the capabilities of OLTP and OLAP systems. This allows HTAP databases to support both transactional and analytical workloads, providing real-time data access and analysis capabilities in a single system. HTAP systems are often used in applications that require both transactional and analytical processing, such as real-time recommendation engines or fraud detection systems.
And that is exactly what Hydra enables Postgres to do. Not only can you have row based and column based tables under the same roof, but you can also convert between them seamlessly. So in case you have a large table getting inserted by in your day to day OLTP transactions, but want to quickly run some aggregate functions on it, you can copy it into columnar format and do your work on that; as such gaining great performance and time savings. CREATE TABLE my_table (i INT8) USING heap; Data can also be converted manually by copying. CREATE TABLE table_heap (i INT8) USING heap; You can always of course explicitly create either a row-based or columnar table by adding the USING keyword: In a demo the Hydra staff run, running a simple Select count(*) on the heap/row based table required 76000 miliseconds while the Columnar one just 344. But by turning your tables into columnar aside of the performance benefits you also get space saving as the data gets compressed. In the same experiment, the heap table consumed 70 gigabyte, while the same turned to columnar required just 16 gigabytes of disk. Before you go gung-ho on it turning everything into columnhs, it's best to be educated about the shortcomings too. It is also append-only. While it supports updates and deletes, space is not reclaimed on deletion, and updates insert new data. Updates and deletes lock the table as Columnar does not have a row-level construct that can be locked. Overall, DML is considerably slower on columnar tables than row tables. Lastly, columnar tables need to be inserted in bulk in order to create efficient stripes. This makes them ideal for long-term storage of data you already have, but not ideal when data is still streaming into the database. For these reasons, it’s best to store data in row-based tables until it is ready to be archived into columnar. With that said, the flexibility that Hydra grants you in using both OLTP and OLAP interchangeably rather than choosing one over the other is what make Hydra stand out; having your cake and eating it too, your transactions and analytics under the same roof.
More InformationRelated ArticlesTurn PostgreSQL Into A Vector Store pg_later - Native Asynchronous Queries Within Postgres
To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Facebook or Linkedin. 
Comments
or email your comment to: comments@i-programmer.info |
|||
| Last Updated ( Monday, 13 November 2023 ) |