| Probabilistic databases - the next big thing? |
| Written by Kay Ewbank | |||
| Friday, 24 June 2011 | |||
|
Never mind NoSQL databases - probabilistic databases are a much more important topic. They are certain to be the next big thing.. or probably certain to be the...
If your applications make use of data, you’ll be painfully aware of the limitations of SQL when dealing with data where you don’t know all the values. It’s fine in a traditional database where a record is a record, someone added it complete with values. If you’re trying to use data from sources such as emails, twitter feeds or blogs to extract information for BI systems, you don’t know what data should be there, how complete it is, and some fields will have imprecise, ambiguous values. Probabilistic databases are those where the value of some attributes, or the presence of some records are uncertain, and known only with some probability. Probabilistic databases are likely to become increasingly important as imprecise business data from the Web has to be included for BI systems. In recognition of this, a team of researchers at Oxford University has developed a system called SPROUT that understands probabilistic data. In addition, in collaboration with the Google Squared team they have developed a web system on top of SPROUT that can integrate uncertain yet dynamic web data with clean offline relational databases and can answer SQL queries over them.
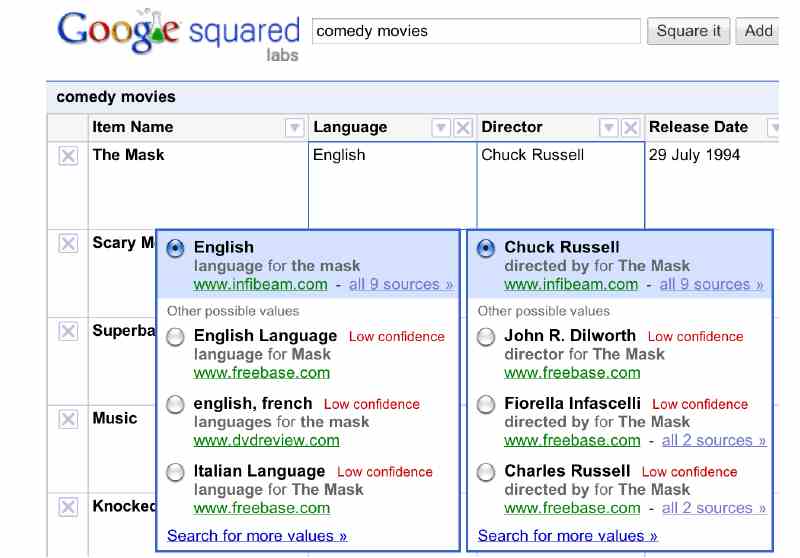
When an SQL query is executed, SPROUT returns a set of answers, and annotates each answer with a probability representing its degree of confidence in decreasing order. The team gives an example of how the web system could be used to find out information about comedy movies. In the image, each row represents characteristics of a movie, such as language, director, etc. For each field, only the value with the highest degree of confidence is displayed. However, if the user clicks on that value, then alternative choices are shown. The SPROUT system will be presented this month in Athens at the SIGMOD conference. The head of the Oxford team, Dan Olteanu has also co-authored a book in which the foundations of probabilistic databases are described for the first time. Probabilistic Databases (Morgan & Claypool, 2011), presents a first unified view of the state of the art in representation formalisms and query processing techniques for probabilistic data. It also surveys advanced work on compilation of queries into decision diagrams, sequential probabilistic databases, indexes, and Monte Carlo databases. The book is intended for researchers, either in databases or probabilistic inference, or as a textbook for an advanced graduate class.
If you would like to be informed about new articles on I Programmer you can either follow us on Twitter or Facebook or you can subscribe to our weekly newsletter.

|
|||
| Last Updated ( Friday, 24 June 2011 ) |