| Program Deep Learning on the GPU with Triton |
| Written by Nikos Vaggalis | |||
| Monday, 02 August 2021 | |||
|
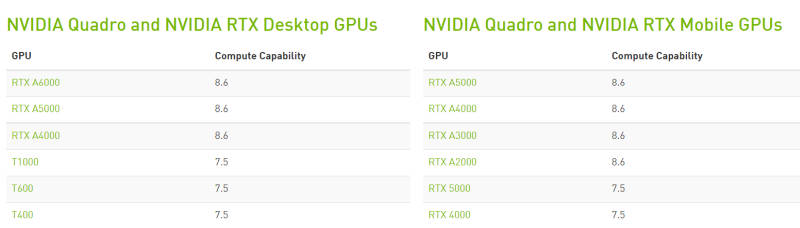
Triton is a new, Python-like, language from OpenAI intended to ease programming for the GPU by providing an alternative to CUDA. NVIDIA's CUDA toolkit provides a development environment for speeding up computing applications by harnessing the power of GPUs, but it requires the code to be written code in C++. As C++ by default is not user-friendly and difficult to master,these properties subsequently rub off on the toolkit itself. Wouldn't it be easier to use a language that is user-friendly to write your GPU-accelerated deep learning applications in? Wish granted by Open AI which has announced: We’re releasing Triton 1.0, an open-source Python-like programming language which enables researchers with no CUDA experience to write highly efficient GPU code—most of the time on par with what an expert would be able to produce. At the moment Triton just supports NVIDIA Tensor Core GPUs such as A100. We had a brief encounter with the powerhouse A100 cards in "GAN Theft Auto - The Neural Network Is The Game", where Nvdia itself loaned to two researchers a DGX station beefed up computer sporting four of the 80 gigabyte A100 GPU cards for a total of 320 gigabytes of VRAM in order to accelerate their research. But to further clarify the "alternative to the CUDA toolkit" claim, while Triton enables researchers with no CUDA experience to write GPU computing and deep learning applications without needing the CUDA toolkit, the GPUs they target must be CUDA-enabled. AMD support is not included in the project's short term plans. That said, Triton also requires those CUDA-enabled GPUs to posses a Compute Capability (a measurement of the GPU's general specifications and available features) of 7.0+. A good chart of the compatibility per GPU can be found here.
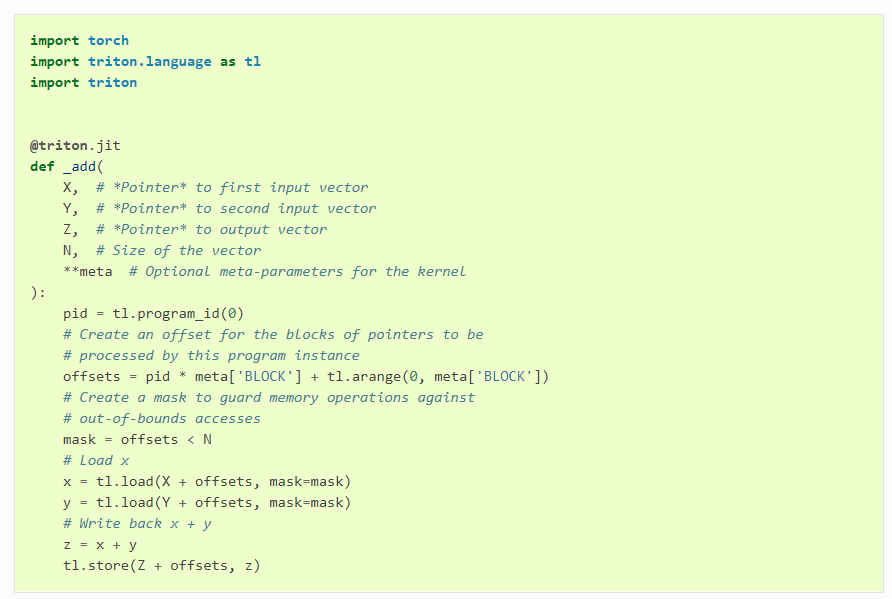
That covers the hardware part. Programming wise, Triton is Python with extensions for GPU programming tasks like matrix multiplication or Vector Addition. As the online examples of the code show, you just import Triton as a library and use its functions on top of Python:
The language aside, Triton is also comprised of two other parts:
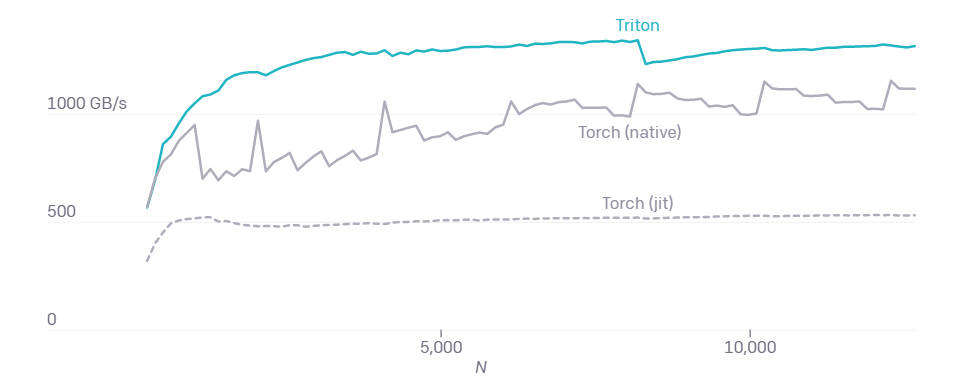
But in the end the burning question is, do you trade performance for programmer productivity by switching from the C++ based CUDA toolkit to Triton? Apart from making GPU programming more accessible to everyone, benchmarks have already shown that Triton produces kernels that are up to two times more efficient than equivalent Torch implementations, achieving peak performance with around 25 lines of Python code. On the other hand, implementing something similar in CUDA would take a lot more effort and would even be likely to achieve lower performance.
So is having the best of both worlds a possibility? That's a Yes with Triton. The project is open-source and available on GitHub. More InformationIntroducing Triton: Open-Source GPU Programming for Neural Networks Related ArticlesGAN Theft Auto - The Neural Network Is The Game Yann LeCun’s Deep Learning Course Free From NYU
To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Facebook or Linkedin. 
Comments
or email your comment to: comments@i-programmer.info |
|||
| Last Updated ( Monday, 02 August 2021 ) |