| Use Rust To Reduce The Size Of Your SQLite Database |
| Written by Nikos Vaggalis | |||
| Monday, 12 September 2022 | |||
|
Meet sqlite-zstd, a Rust library that compresses your database many fold, leading to great savings in size while conserving its search capabilities intact. As pointed out in "In Praise Of SQLite", SQLite is not a toy database: Despite its compact size and absence of the client server model, SQLite is a RDBMS with all the features that make something relational - that is tables, indexes, constraints, triggers, transactions and the like. However, there are few built-in functions compared to PostgreSQL or Oracle. SQLite doesn’t have any compression features. This has changed with the Rust-based library, sqlite-zstd which promises to: provide transparent dictionary-based row-level compression that allows compressing a sqlite database's entries almost as well as if you were compressing the whole DB file, while at the same time retaining random access. Suffice it to say that we are all aware of the benefits of compressing data, be it that of a PDF document, a humble ZIP file or in this case a database. As a proof of concept and walkthrough of the tool, I'll work with a sample database used by the Joplin note taking app. Well work with Windows because it offers a more straightforward experience. The sample database.sqlite is 2.6 GB in size.Some would say 'what kind of notes do you have that occupy that much space?'. It is true that that number sounds extravagant. It is like that because Joplin allows you to scrape any web page you encounter and store it as markdown inside the database. Since I'm a person with a wide array of interests, when I find something interesting I keep a copy of it. As such the number of pages I dump into Joplin accumulates and the size of the database increases. Therefore sqlite-zstd was a godsend. Of course your use case might be different; the library's main use case example online showcases compressing a database with 7 million book entries in JSON format, and does so by reducing its size from 2.2GB to 550KB! But in order to get to that, the first hurdle was to find the 64-bit version of sqlite's CLI, sqlite3, since the official build is offered only in 32-bit, and since zstd is a 64-bit library it needed the corresponding version. While you can build it manually, why go to that trouble when someone has already done it for you? Hop over to the SQLite shell builder Github repo and download the latest 64-bit release for Windows (Ubuntu, MacOS as well). Having got hold of the CLI it's time to execute it to load both the library and sample database. After that we will enable the transparent row-level compression of the 'body' column, the column that keeps the bulk of the text of the 'notes' table. Saying that,you can invoke the transparent row-level compression function several times on the same table with different columns to compress. You call it like this:
The following differences apply when compression is active:
Also, 'dict_chooser' is an SQL expression that decides how to partition the data. Example partitioning keys:
I went with the simplest case of 'a' which means that all the rows are compressed with the same dictionary. And now in code:
Unfortunately I got an error back :
After some digging I understood that the unquoted order entry was being considered as a reserved SQL word and thus the error. Changing order to 'order' made the SQL Create Trigger statement pass.This, of course, was an edge case due to the special column name that the Joplin app is using and if it were another app I might not even have noticed. But in any case, the quoting mechanism should be fixed library-side, therefore I opened an issue on its GitHub repo. Until it is fixed and a new version is released, what can you do? I renamed the column just to make it pass:
Then run sqlite_zstd::transparent again, which now runs to completion. As already said, sqlite_zstd::transparent just enables the compression. The real work is done by:
followed by:
in order to reclaim the free space. After the couple of minutes that it takes for the operations to complete, let's observe the gains. From 2,663,996 KB original size to 1,912,900 KB. And that is without tweaking the settings and using the default dictionary chooser. Not bad! Let's see if the search works too : select * from notes where body like 'python%' limit 1 ; It works like a charm! Compression enables you to save storage space by reducing the size of the database, but it has a performance impact because the data must be compressed and decompressed when being accessed. As such the library must be loaded whenever the database is accessed. For example, let's see how Joplin behaves when trying to load the compressed database (assuming the renaming of the order column and the that 'notes' has became a view instead of a table) - it has no impact on its functionality.
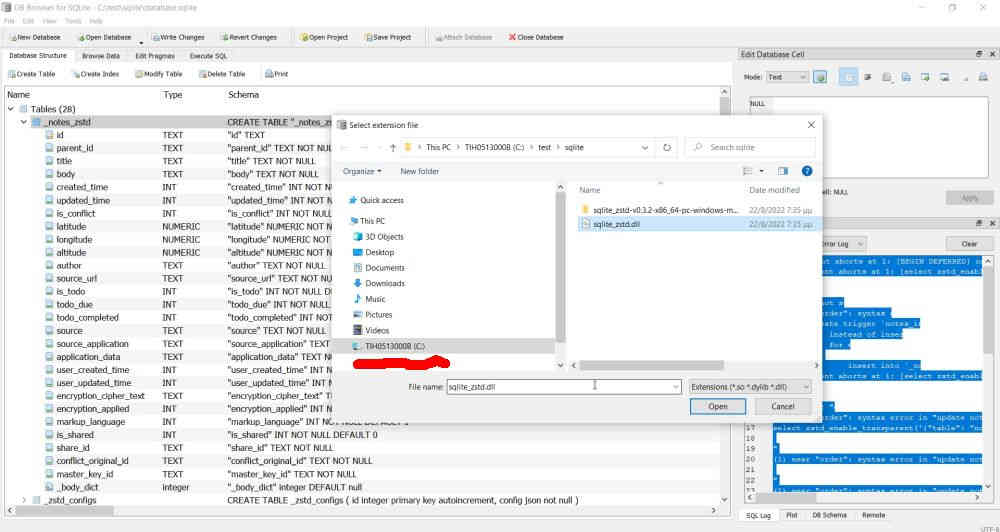
Bonus materialInstead of fiddling with the sqlite3 CLI you can do the same easily and GUI-based by using Db browser for SQLite. Just load the database and the extension through the GUI.Then run your SQL on it.
The big conclusion here is that any application that can side-load this library can reduce the size of its database by 50 to 95% while not affecting its basic functionality. Sure the performance impact is there, but considering most operations still run at over 50k per seconds you’ll probably have other bottlenecks. There’s other optimizations to be done, but the same method should work for other databases, with barely any modifications required for say PostgreSQL. Is this the humble start of a greater impact on the state of database technology ? More InformationRelated ArticlesTake The Beginner's Series to Rust
To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Twitter, Facebook or Linkedin. 
Comments
or email your comment to: comments@i-programmer.info |
|||
| Last Updated ( Monday, 12 September 2022 ) |